進化を続ける人工知能の世界では、エージェントシステムの品質が日々高度に成長し続けています。
エージェントシステムとは、システムの環境中のフィードバックから意思決定を行い、学習することができる自律型のシステムのことを指します。与えられた状況から自ら意思決定し処理を実行するソフトウェアのイメージを持っていただければ大丈夫です。
このエージェントシステムの成長と同時に、検索拡張世代(RAG)アプリケーションがより複雑になるにつれ、これらのシステムの重要な構成要素は「メモリ」になりました。
AIエージェントは、効率的に実行し、新しい状況に適応し、情報に基づいた意思決定を行うために、メモリに依存しています。
しかし、これらのシステムへの単一のリクエストは、ボンネットの下で何百もの呼び出しを生成する可能性があり、アプリケーションを構築し維持するAIエンジニアリングチームにとって、問題をデバッグし、それらがどのように出力に至るかを解析していくことは困難です。
より多くの企業がLLMアプリケーションを採用し、堅牢なエージェントシステムと統合し始める中、チームがアプリケーションのパフォーマンスを評価・分析し、かんたんに改善できることが必要不可欠です。
そこで「Arize AI」と「MongoDB」の組み合わせをご紹介します。
この2つは、AIエンジニアが自信を持ってLLMアプリケーションを開発し、展開できるよう支援します。
大規模言語モデル(LLM)が進歩し続ける中、効率的でスケーラブルなメモリシステムが必要になります。特にAIエージェントのメモリを管理する上で、ベクターデータベースはこの文脈において非常に重要です。
MongoDBは、完全なドキュメント型データストアと、統合された全文検索とベクトル検索機能をサポートする堅牢なクエリAPIを提供しています。この高性能なクエリAPIによって、これらのシステムを実装するための強力な基盤を構築することが可能になります。
AIエージェントを構築し、本番環境でスムーズに稼働させ続けることが難しいことだと感じていませんか?
特にLLM(大規模言語モデル)を扱う場合、まだ未開拓の領域であり、多くの人が試行錯誤を通じて解決策を模索しています。本番環境でリリースした後でも、システムが不具合を起こしたり、予期しない動作をしたりすることがあります。
そのたびに不具合の原因を調査し、改修を重ね、再び挑戦する必要があります。開発と本番環境の境界線があいまいに感じられ、行ったり来たりを繰り返すことも少なくありません。
そんなときに頼りになるのが「Arize」というツールです。このツールキットは機能が非常に充実している反面、どの機能をいつ活用すればいいのか迷います。
私たち自身もAIを構築する際に多くの苦労を経験してきたため、この複雑さを乗り越えるお手伝いをしたいと思っています。
今回は、ArizeとPhoenixを活用してAIアシスタント「Copilot」を開発・改良・改善していく方法を分かりやすく解説していきます。成功を支える重要な機能やワークフローについて、順を追ってご紹介します。
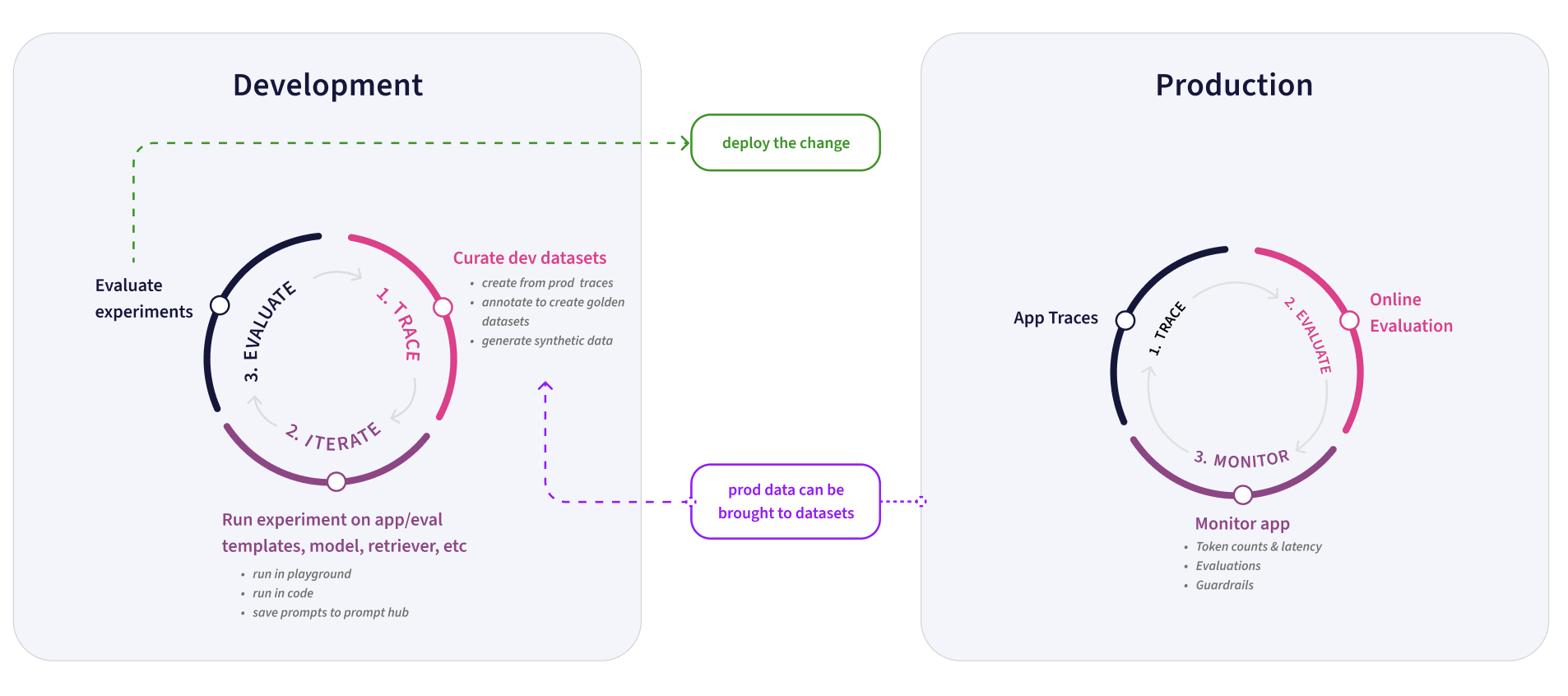
AIエージェントのテストと反復改善
新しいスキルの開発や機能のテスト・反復改善において、私たちの頼りになるツールがPhoenixです。
Phoenixのトレース機能は、開発中に非常に貴重な洞察を与えてくれます。
新しいスキルを構築する際には、まず基本的なスケルトンとして機能するプロトタイプ(概念実証)から始めます。その後、テストと反復改善へ進みます。
私たちは、Copilotのコンポーネントを直接ノートブックに統合したテストフレームワークを構築しました。
これによりテストクエリを実行することが容易になり、トレースをPhoenixですぐに確認できるようになります。
この仕組みを使い、以下の3つを確認します。
・データ関数がArizeから正しいデータを取得しているか
・ルーターが適切に関数を呼び出しているか
・関数が正しい引数を受け取っているか
また、応答が期待通りかどうかも同時にチェックします。要するに、Phoenixのトレースは、何がうまく機能していて何が問題かを理解するのに役立ち、迅速かつ自信を持って反復改善を進めることを可能にします。
私たちにとって、Phoenixのトレースは開発で最も頻繁に使うツールの一つです。
この有能な機能が本番環境で稼働し始めたら、Arizeが主なツールとなります。
特にトレース機能は、ユーザーがCopilotとどのようにやり取りしているか、それが期待通りに動作しているかを確認するため、日常的に使用しています。
ここで重要になるのがデータの『フィルタリング』です。例えば、ユーザーのメールアドレスでフィルタリングして、内部利用と顧客とのやり取りを区別することがよくあります。その後、アプリケーションが実行したステップを確認し、それらが期待通りであることを確かめるためにトレースを精査します。
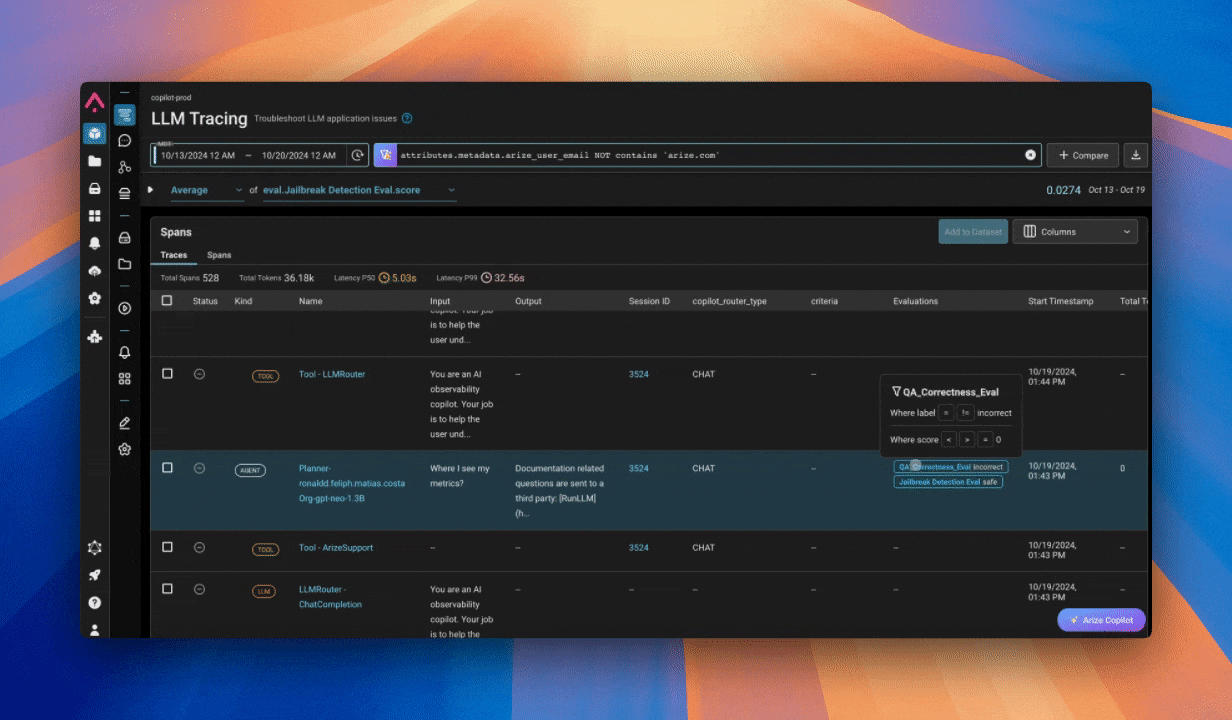
以前、トレーシングエンドポイントへの変更が原因で、いくつかの生成スキルに不良が生じ、大規模な不具合が発生したことがありました。
この問題を特定するために、トレースページでエラートレースをフィルタリングしました。それらを確認したところ、問題点が明確になり、迅速に解決することができました。
しかし、今後同じような状況を避けるために、エラーが5回以上発生した場合に通知を送るエラーモニターを設定しました。
これにより、さらに迅速に問題を発見・修正できるようになりました。また、ジャイルブレイク試行のような潜在的な問題を検出するために、評価ラベルも監視しています。
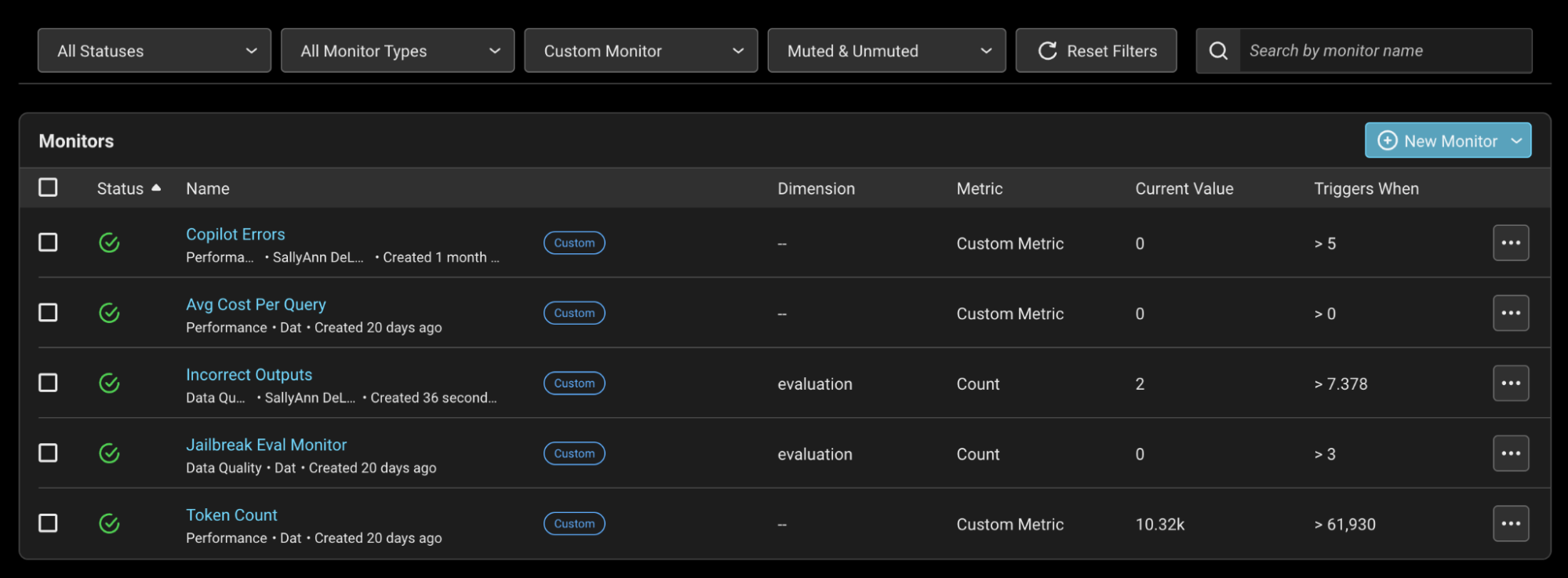
ダッシュボードとモニタリング
私たちの日々のワークフローの中で、もう一つの重要なことがあります。
それは、Arizeのダッシュボードをチェックして、使用パターンや利用状況をモニタリングすることです。
具体的には、Copilotのリクエスト数、平均クエリコスト、トークン数といった高レベルの指標を追跡します。これらの指標は、トラフィックやコストを把握するのに役立ちます。また、エラーレートもダッシュボード上で綿密に監視している重要な指標の一つです。
ダッシュボードで特に有用な洞察を得られる部分の一つが、スキルやユーザーごとのリクエスト数を追跡する機能です。このデータを視覚化することで、どのユーザーが最も活発に利用しているかを把握しやすくなり、フィードバックを集める際にも役立ちます。
また、どのスキルが最も注目を集めているかも一目瞭然です。初期段階では、このデータを活用して開発の投資先を特定し、最も効果的なスキルにリソースを集中させることができました。
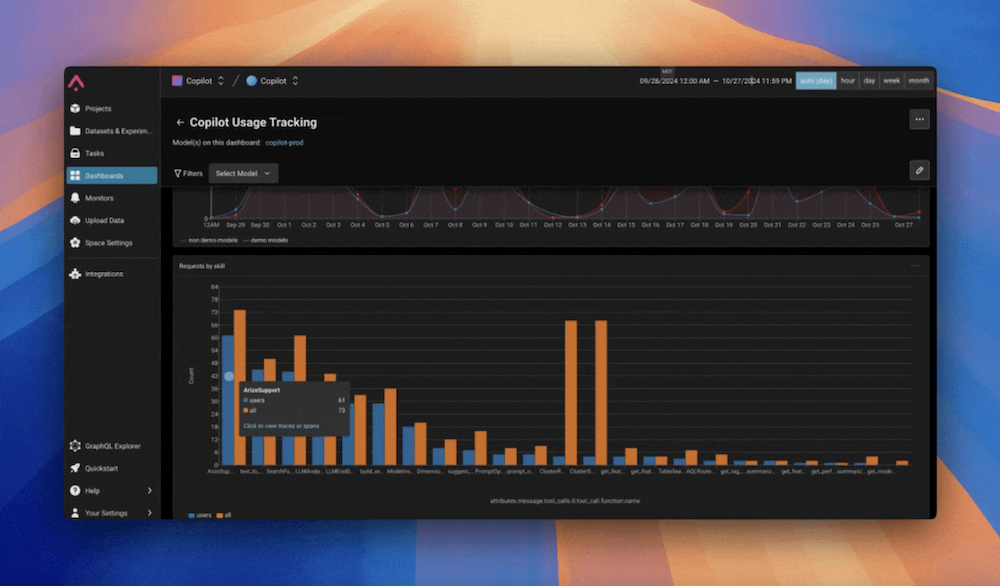
エージェントのパフォーマンス評価
本番環境でのCopilotのパフォーマンスを把握するために、新しいデータに対して自動評価を実行するオンラインジョブを設定しています。
最初は、Phoenixの評価ライブラリを使ったシンプルなQA正確性評価から始め、Copilotがユーザーのクエリに正しく回答しているかを確認しました。
これにより、トレースをフィルタリングして詳細に分析し、パフォーマンスを時間をかけて改善することができました。また、注釈ツールを使用して評価結果をレビューし、不正確な評価を将来の改良に向けてマークすることも可能となります。
すべてのスキルが一般的なQA正確性評価に適合するわけではないため、その後、スキルごとに特化した評価を構築し、追加の評価レイヤーを導入しました。評価セットを精緻化することで、より包括的なモニタリングを実現しています。
データセットと実験の活用
日々のトレースレビューは、ユーザーの行動に関する仮説を立て、直感を養うのに役立ちます。このプロセスで特に便利なのがデータセット機能です。トレースをレビューする際、問題のあるトレースやバグのある動作、理想的でない結果など、パターンをよく見つけ、それらをデータセットに保存して後のテストに活用します。
例えば、サポートされていないユーザーのクエリをデータセットに集めることで、Copilotに欠けている機能を特定する手助けになります。データセットは様々な用途で用いられ、テスト用の例を集めるためにも、実験を行う開発ワークフローの中で活用するためにも使用されます。
実験は、モデルの更新やA/Bテストなど、変更をテストする際のメジャーな方法です。データセットと実験を組み合わせることで、アプリケーションの変更を体系的にテストできます。アプリケーションの一部を再現するタスクを定義し、成功を測定するために評価者を使用します。
問題解決や改善の検証において、実験は変更の影響を測定し、物事が順調に進んでいることを確認するための構造化された方法を提供してくれます。
実験によるモデル切り替えの処理
5月にOpenAIがGPT-4-oをリリースした際、私たちはその性能、速度、セキュリティの向上を活かすことを楽しみにしていました。しかし、モデルを切り替えることがもたらす影響を予想していませんでした。
生成AIが持つ多くのスキルが失敗し始め、いくつかは奇妙な反応を示し、指示を無視し始め、さらには完全に動作しなくなりました。
すぐに、すべての機能を手動でテストし、発見したことを文書化し、すべてが修正されるまで反復する必要があることが明らかになりました。これは苦痛を伴うプロセスでした。
現在では、実験を通じてモデルの切り替えなどの変更に対して、より体系的なアプローチを取ることが可能になりました。私たちはゴールデンデータセット(現実的なユーザーの質問と、専門家の回答を集めた質の高いデータセットのこと)を作成し、実際の設定を模倣するタスクを設定し、新しいモデルがすべてのゴールデン入力に対して正しい結果を出すかどうかを評価します。これにより、どこで問題が発生するか、どのように調整すべきかを正確に予測できるようになります。
また、実験は継続的な開発にも活用しています。例えば、ダッシュボードを確認し、AI検索が最も投資する価値のあるスキルであると判断した後、完全にサポートされていないクエリを試みたユーザーのトレースを収集しました。
そこで、ユーザーの期待に関する明確な3つのカテゴリー(テキストフィルター、テーブル検索、分析)を特定しました。そこで、3つの新しいスキルを開発し、それらを処理できるようにルーターを更新しました。
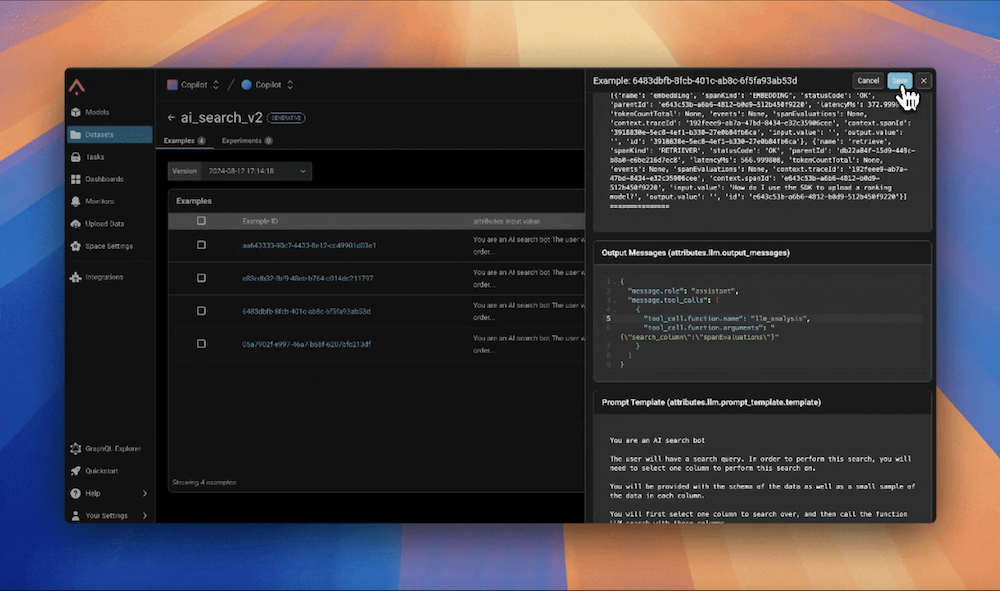
これらの更新を盲目的にリリースするのではなく、私たちはデータセットと実験を活用して変更を徹底的にテストしました。
新しいルーターが正しい関数を選択し、適切な引数を渡していることを確認するために実験を構築しました。また、各新しい関数が期待通りに動作しているかを確認するために実験も実施しました。このデータ駆動型の反復的アプローチは私たちにとって画期的なものであり、実際の洞察に基づいて製品を洗練させ、リリース前に変更を自信を持って検証できるようにしました。
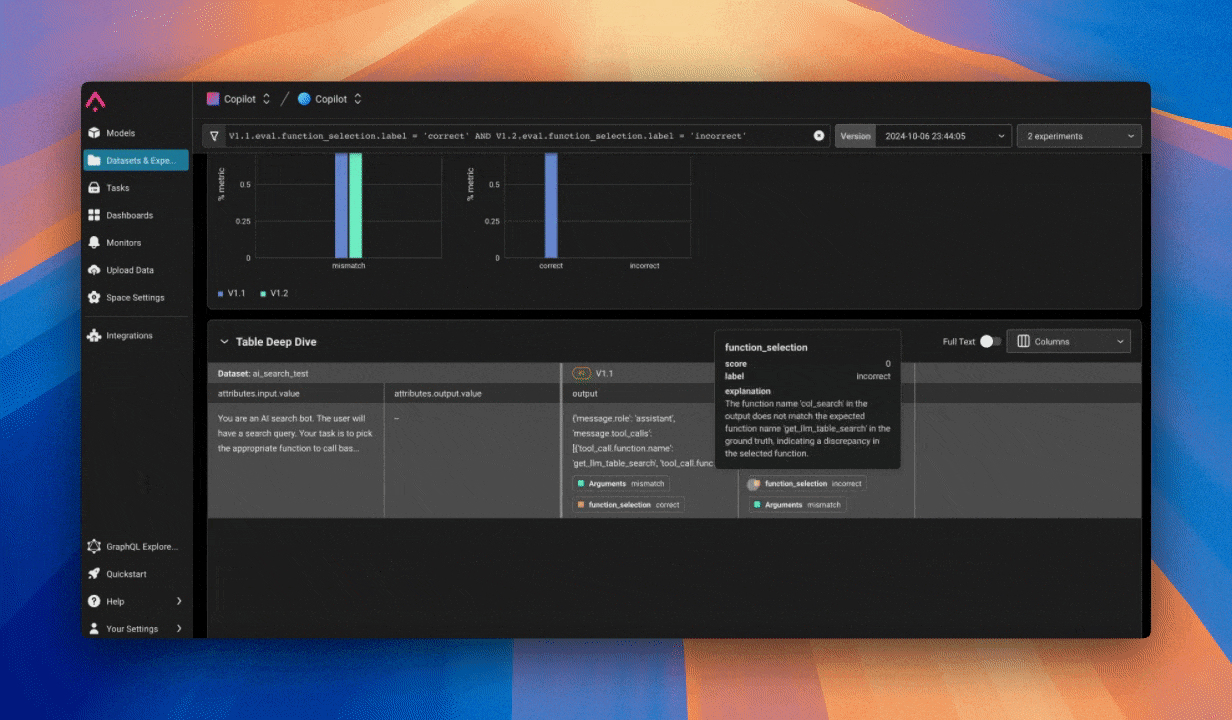
CI/CDパイプラインによる自動化
このプロセスをさらに効率化するために、Gitアクションを使用してCI/CDパイプラインで評価ワークフローを自動化しました。
ルーターとスキルテスト用の実験スクリプトを作成し、リポジトリにワークフローファイルを追加しました。これで、AI 検索コードのディレクトリにプッシュされるたびに、これらの実験が自動的に実行されます。Gitのチェックと同様に、実験は合格するか失敗するかのいずれかです。評価者の平均スコアが0.7未満の場合、チェックは失敗します。
この自動化されたセットアップにより、どんな変更も十分にテストでき、最小限の手動作業で済むことが確信できます。今後は、AIの持つ全てのスキルに実験を実施し、変更がどのような影響を与えるかをきちんと理解可能にすることを目指しています。
継続的な監視とトラブルシューティング
私たちが実験のために作成した評価ツールは、本番環境でもオンラインジョブを通じて実行される evals として使用されています。これにより、反復中もスキルが稼働した後も継続的に監視を行うことができます。もしパフォーマンス低下が目立ち始めた場合、通常は失敗したevalの数が増加していきます。その際、スキルやトレースタイプでフィルタリングし、トレースを詳しく調べてトラブルシューティングを開始するのが一般的です。
このプロセスは簡単です。問題が特定できたら、プロンプトや関数に関するものであれば、トレースから直接Prompt Playgroundに移動します。
Playgroundは自動的にプロンプトテンプレートと変数が読み込まれ、迅速に編集を行い、問題を解消できるかテストすることが出来ます。問題のあるトレースのデータセットがあれば、それをPlaygroundに読み込んで、すべての例で新しいプロンプトをテストし、問題が解決されたことを確認します。
もし問題が関数呼び出しに関するものであれば、Playgroundも役立ちます。ルータープロンプトとツール定義を読み込んで、必要に応じて調整し、ルーターが正しい引数で正しい関数を呼び出す能力をテストします。Playground内で正確な環境を再現できることにより、本番環境に変更を反映させる前に、その変更に確信を持つことができます。
【まとめ】コード・コミット・反復
テストを実行して結果に満足したら、コードをコミットし、これまでにご説明したプロセス全体を開始します。
PhoenixトレースやArizeダッシュボードから実験、Prompt Playgroundに至るまで、これらのツールは私たちが継続的に反復し、改善し、Copilotを洗練させることを可能にします。これらがなければ、同じレベルの自信や速度で運用することはできません。
AIエージェントの開発は、一方通行の単純なプロセスだけではありません。
私たちはこれらのワークフローを開発と本番環境の両方で不可欠な部分として使用し、ユーザー体験を改善する方法を常に探求しています。これらのワークフローを共有することで、開発者である皆さんが開発プロセスに同様のアプローチを取り入れることを願っています。