アパルナ・ディナカラン、共同創設者兼最高製品責任者
LLMが持つ5つの特徴と能力について
2022年11月、ChatGPTがデビューし、多くの人が大規模言語モデル(LLM)の能力を初めて目にしたとき、技術業界は永遠に変わった。
その時以来、誰もがその一部を欲しがっている。例えば
- エクスペディアがLLMベースの旅行プランナーを開発中
- Notionはインラインコンテンツ生成を提供
- StripeはChatGPTを使って詐欺を管理し、コンバージョンを増やそうとしている。
- DuolingoとKhan AcademyはLLMを使って学習を強化しようとしている。
マイクロソフト、メタ、グーグルのような大企業が自社の製品にLLMを使用していることは言うまでもない。アマゾンは現在、販売者が説明文を自動生成できるようにする競争に参入している。
これらの製品は様々な成熟段階にあるが、機械学習システムのデモと実際の製品との間に隔たりがあることは明らかだ。機械学習を製品化することは常に難題であったが、LLMによってその難題はさらに難しくなった。
LLMの典型的な使用例とは?
LLMアプリケーションに共通するユースケースは数多くある。ここではその一部を紹介し、それぞれの詳細については今後の記事で取り上げる。
チャットボット
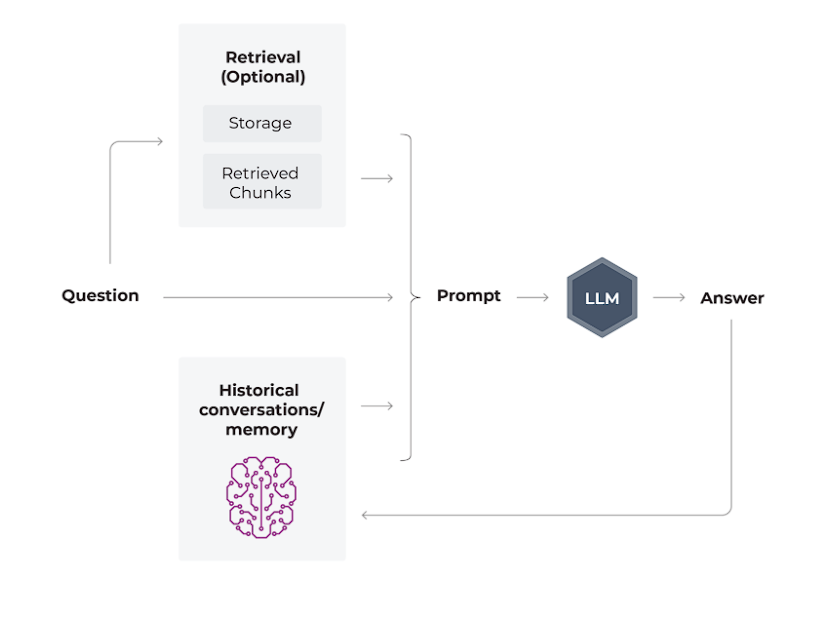
ChatGPTは当初、チャットボットを通じて大衆にLLMを紹介したので、このユースケースは非常に一般的です。ユーザーが質問し、システムが情報を検索してプロンプトを充実させ、LLMが応答を生成する。
構造化データ抽出

構造化データ抽出のユースケースでは、LLMは非構造化入力をスキーマとともに受け取り、情報の構造化表現を出力する。これは、より大規模なソフトウェア・システムのコンテキストで有用であることが多い。
要約

自然言語処理(NLP)は長い間、優れた要約の解決策を模索してきた。従来の抽出的、抽象的要約技術の多くは、現在ではLLMに取って代わられている。
その他の使用例
これらに加え、コード生成、ウェブスクレイピング、タグ付けとラベリングなど、より専門的なユースケースも多い。
LLMは、Q&Aアシスタントやチャット・ツー・ペイなど、より複雑なユースケースにも採用されている。これらは、高次の目的を達成するステップ(スパン)で構成される。スパンは、他のLLMユースケース、伝統的な機械学習システム、または非MLのソフトウェア定義ツール(電卓のような)とすることができる。
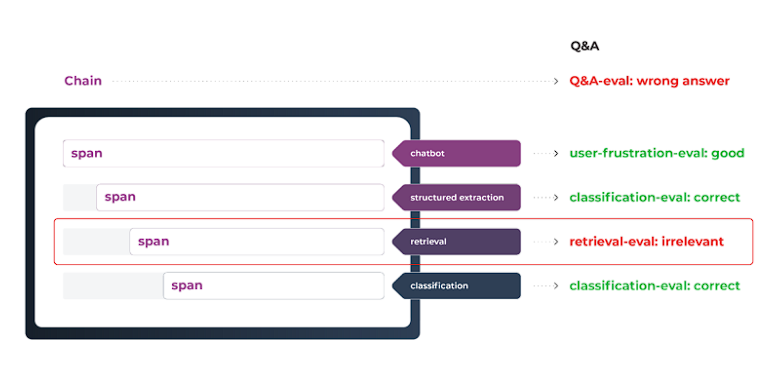
これらのワークフローは便利だが、複数のシステム上で適切なオーケストレーションを必要とするため、非常に複雑でもある。これらのワークフローは多くのコードを必要としないが、その簡潔さを単純さと混同してはならない。たとえ数行でも、エラーの可能性のある非常に長い計算の連鎖を引き起こす可能性がある(挿入図参照)。
この複雑さが、今日のLLMプロジェクトが「ツイッター・デモ」から顧客の使用に至るまでに経験する困難につながっている。
LLMにはどのような問題があるのか?
よくある問題をいくつか挙げてみよう。
- 幻覚: トレーニングにおけるモデルの目的は、次の数文字を予測することである。回答の正確さはむしろ副次的なものである。そのため、幻覚、つまり事実に基づかないでっち上げの回答はよくあることであり、予測不可能である。あなたはLLMを近道として使っているが、もしそのLLMに書いてあることをすべてダブルチェックしなければならないとしたら、それほど役に立たないかもしれない。しかし、確認しなければ、本当に困ったことになるかもしれない。
- 電話の多発: 幻覚の問題を解決することさえ、より大きな問題を引き起こす可能性がある。例えば、前述の問題を回避する一つの方法として、LLMに自身の結果を分析するよう求める「リフレクション」がある。このテクニックは強力だが、ただでさえ複雑なシステムをさらに複雑にしてしまう。1回の呼び出しではなく、呼び出しの連鎖が発生するのだ。これはどのスパンでも同じなので、上で話した複雑なユースケースの場合、複数のスパンの中に複数のコールが存在することになる。
- 独自データ: 独自データをミックスに加えると、事態はさらに面白くなる。複雑な質問に答えるために必要なデータの多くが、プロプライエタリなものであるという現実がある。LLMのアクセス制御システムは、従来のソフトウェアほど堅牢ではない。プロプライエタリな情報が誤って回答に入ってしまう可能性があるのだ。
- 応答の質: 回答の質は、他の理由でも最適でないことがよくある。例えば、口調がおかしいとか、詳細が不適切であるなどです。ほとんど構造化されていない回答の質をコントロールするのは非常に困難です。
- コスト 次に、部屋の中の象がある:コスト。スパン、リフレクション、LLMへの電話などをすべて合わせると、かなりの金額になる。
- 第三者モデル: サードパーティプロバイダーを通じてアクセスされるLLMは、時間とともに変化する可能性がある。APIが変更されたり、新しいモデルが追加されたり、新しいセーフガードが導入されたりする可能性があり、これらすべてがモデルの振る舞いを変える原因となる。
- 限られた競争優位性: より大きな問題は、LLMの訓練と維持が難しいことだろう。したがって、あなたのLLMモデルは競合他社と同じであり、本当に差別化できるのは、迅速なエンジニアリングと独自データへの接続である。それらをうまく使っていることを確認したいものです。
これらは難しい問題だが、幸いなことに、すべてに取り組むための第一歩は同じである。
LLMの観測可能性とは?
LLMの可観測性とは、LLMベースのソフトウェアシステムのすべてのレイヤー(アプリケーション、プロンプト、レスポンス)を完全に可視化することである。
LLM観測可能性とML観測可能性の比較
大規模な言語モデルはMLに新しく参入したものだが、旧来のMLシステムと多くの共通点があるため、観測可能性はどちらの場合でも同様に作用する。
- MLの可観測性と同様に、埋め込みは非構造化データを理解するのに非常に有用であり、過去に説明したような埋め込み技術はLLMではさらに重要である。
- モデルの性能を理解し、それを経時的に追跡することは、相変わらず重要である。データ・ドリフトとモデル・ドリフトを理解することは、セクション3で取り上げた理由から重要である。
- データ収集(プロンプト/回答の履歴)は、ドリフトを理解し、モデルを微調整する上で、LLMでも依然として非常に重要である。
- しかし、いくつかの重要な違いもある:
- LLMの導入モデルは従来のMLとは大きく異なる。LLMの導入モデルは、より伝統的なMLとは大きく異なります。ほとんどの場合、LLMにサードパーティーのプロバイダーを使用している可能性が高いため、モデルの内部を見ることはできません。
- 評価は、ランキングではなく生成の評価であるため、根本的に異なる。そのため、まったく新しいツールセットが必要になり、そのうちのいくつかは、そもそもLLMによってのみ可能になる。
- ベクトルストアを使用している場合(そしてほとんどの検索ケースはそうである)、最適な検索を妨げ、その結果、あまり理想的でないプロンプトを生み出すかもしれないユニークな課題がある。
LlamaIndexやLangChainのようなエージェント型ワークフローやオーケストレーションフレームワークは、異なる観測可能性アプローチを必要とする独自の課題を提示している。
大規模言語モデル観測可能性の5つの柱の紹介

LLMの観測可能性の5つの柱を重要な順に理解しよう。それぞれが独自の研究や作品に値するが、ここでは簡単に要約する。
LLMエバール

評価とは、回答がプロンプトにどれだけうまく答えられたかの尺度である。これはLLMの観測可能性において最も重要な柱である。
個々のクエリに対して評価を行うこともできますが、通常はパターンを見つけることから始めます。例えば、プロンプトの埋め込み可視化を見て、良いレスポンスと悪いレスポンスを分けると、パターンが浮かび上がってきます。
- そもそも、その対応が良かったかどうかを知るにはどうすればいいのか。評価する方法はいくつかある。ユーザーから直接フィードバックを集めることができます。これは最もシンプルな方法ですが、ユーザーがフィードバックを提供したがらなかったり、単に忘れてしまったりすることがよくあります。また、これを大規模に実施する場合、他の課題も生じます。
- もう1つの方法は、LLMを使用して特定のプロンプトに対する回答の質を評価することです。これはよりスケーラブルで非常に有用であるが、典型的なLLMの欠点がある。
問題領域を特定したら、システムに問題を与えているプロンプトを要約します。これは、プロンプトを読んで類似点を見つけるか、別の LLM を使用することで行うことができる。
このステップのポイントは、単純に問題があることを確認し、どのように進めるかの最初の手がかりを与えることである。このプロセスを簡単にするために、ArizeのオープンソースPhoenixフレームワークを使うことができる。
エージェント型ワークフローにおけるトレースとスパン
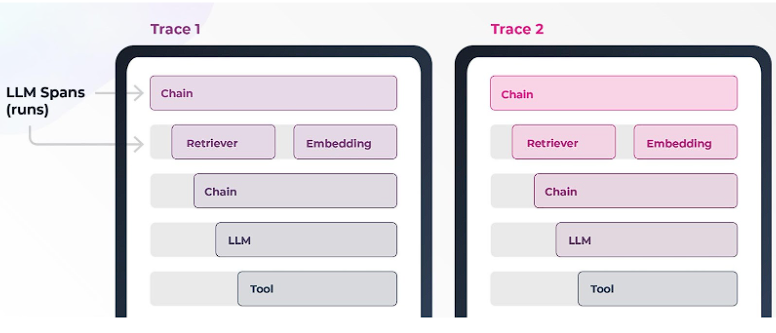
より複雑なワークフローやエージェント的なワークフローでは、スパン内のどの呼び出しや、トレース(ユースケース全体の実行)内のどのスパンが問題を引き起こしているのかが明らかでない場合があります。問題を絞り込む前に、いくつかのスパンで評価プロセスを繰り返す必要があるかもしれない。
この柱は、調査している問題を切り離すために、システムに深く潜り込むことにあります。これには、検索ステップやLLMユースケースステップが含まれるかもしれません。
プロンプトエンジニアリング
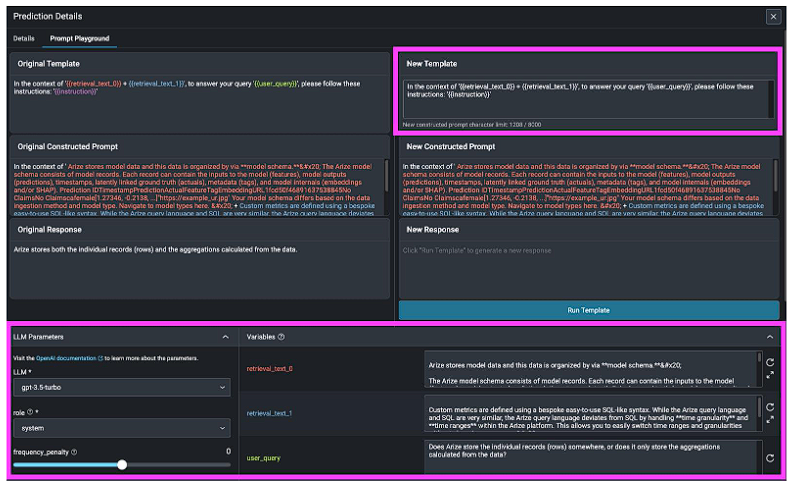
Arizeにおけるプロンプト・テンプレート間の回答の反復と比較の例
迅速なエンジニアリングは、アプリケーションのパフォーマンスを向上させる最も安価で、最も速く、そしてしばしば最も活用度の高い方法です。
これは人間の思考方法に似ている。単独で “あれは誰だ?”という質問に答えるのはかなり難しいでしょう。しかし、もう少し文脈を理解すれば、”アポロ11号の着陸船の隣にいる、月にいるのは誰だ?”となります。- と聞けば、妥当な答えの数はすぐに絞られる。
LLMはアテンション・メカニズムに基づいており、アテンション・メカニズムの背後にある魔法は、関連する文脈を拾い上げることに長けているということだ。あなたはそれを提供するだけでいいのです。
製品アプリケーションで厄介なのは、適切なプロンプトを得るだけでなく、それを簡潔にしなければならないことだ。LLMは1トークンあたりの価格が決まっており、規模を拡大したアプリケーションでプロンプト・テンプレートのトークン数を倍にすると、非常に高くつく可能性がある。もう一つの問題は、LLMはコンテキストウィンドウが限られているため、プロンプトで提供できるコンテキストが限られていることだ。
検索

パフォーマンスを向上させるもうひとつの方法は、より適切な情報を入力することだ。これは少し難しく、コストもかかるが、信じられないような結果をもたらすことがある。
より関連性の高い情報を取り出すことができれば、プロンプトは自動的に向上する。しかし、情報検索システムはもっと複雑だ。より良い埋め込みが必要なのかもしれない。検索を多段階プロセスにできるかもしれない。
そのためには、まず文書を要約して埋め込む。そして、検索時には、まず要約から文書を見つけ、次に関連するチャンクを取得する。あるいは、文章レベルでテキストを埋め込み、LLM合成時にそのウィンドウを拡張することもできる。あるいは、単にテキストへの参照を埋め込むこともできるし、バックエンドで情報を整理する方法を変えることもできる。埋め込みをテキストチャンクから切り離すには、多くの可能性がある。
微調整
最後に、モデルを微調整することができます。これは基本的に、より正確な使用状況に沿った新しいモデルを生成します。ファインチューニングは高価で困難であり、基礎となるLLMやシステムのその他の条件が変化した場合には、再度行う必要があるかもしれません。これは非常に強力なテクニックですが、この冒険に乗り出す前に、ROIを明確にする必要があります。
観測可能なアプリケーションの設定方法
アプリケーションをセットアップする普遍的な方法はありません。多くの異なるアーキテクチャとパターンがあり、アプリケーションのセットアップはその特殊性に大きく左右されますが、ここではいくつかのポイントを紹介します。
- 人間のフィードバック: 幸運にもユーザーからのフィードバックを集めることができたなら、将来の分析のためにフィードバックと回答を保存しておくべきである。そうでない場合は、LLM支援による評価を生成し、それを保存することができます。
- 複数のプロンプトテンプレート: 複数のプロンプトテンプレートがある場合は、それらを比較する。そうでない場合は、プロンプトテンプレートを繰り返し、パフォーマンスを改善できるかどうかを確認する。
- 検索拡張世代(RAG)を使用する: 知識ベースにアクセスできる場合は、そこにギャップがあるかどうかを評価する。そうでなければ、検索されたコンテンツが関連性があるかどうかを評価するためにプロドログを使用する。
- チェーンとエージェント: スパンとトレースのログを取り、アプリがどこで壊れているかを確認する。それぞれのスパンについて、人間のフィードバックに関する上記の提案を使用する。
- 微調整: ファインチューニングを行う場合、ファインチューニングに使用できるサンプルデータを見つけてエクスポートする。
結論
大規模な言語モデルは、この1年で使用例も関心も爆発的に増加した。これらがもたらすチャンスはエキサイティングであり、これらのテクニックのパワーはまだ実現され始めたばかりである。抽象化されているため実装はかなり簡単だが、同じ抽象化と固有のシステムの複雑さにより、システムの各要素がどのように動作しているかをよく理解することが不可欠となる。要するに、信頼性の高いLLMアプリを実行するには、LLMの観測性が必要なのだ。