執筆者: Jay Revels
評価駆動開発とは?
AIエージェントを活用したアプリケーションを、さらに高いレベルへと引き上げる準備はできていますか?
本記事では、開発ライフサイクル全体を通じてエージェントのパフォーマンスを向上させるための重要な手法である「評価駆動開発」について紹介します。
このフレームワークを取り入れることで、ユーザーにとって価値のあるAIエージェントを本番環境へスムーズに展開できるようになります。
以下のような課題を抱えていませんか?
「プロンプトの調整が必要か?」
「ワークフローのロジックを見直すべきか?」
「いっそ言語モデル自体を変更すべきか?」
評価駆動開発を採用すれば、これらの課題に体系的にアプローチでき、場当たり的な試行錯誤を繰り返す必要がなくなります。代わりに、実験・分析・改善のプロセスを明確にし、効率的にエージェントを最適化できるようになります。
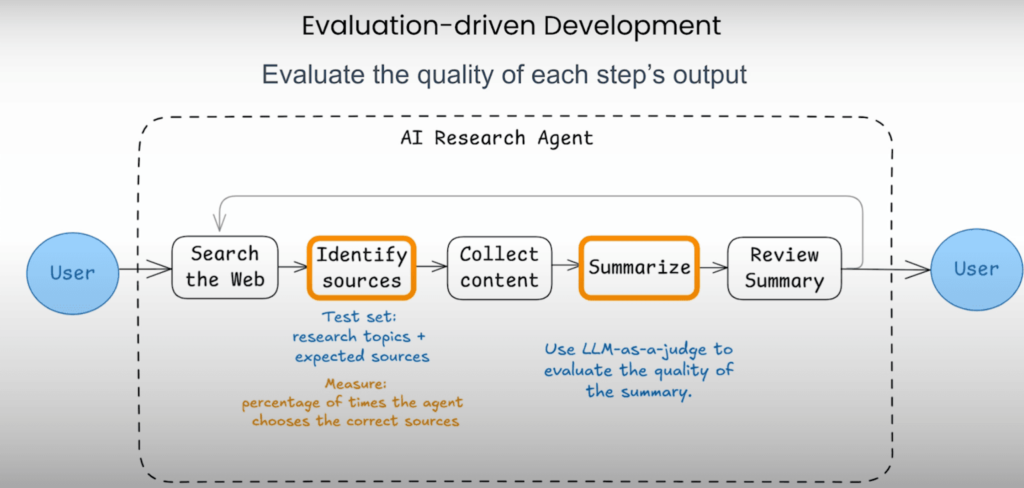
例えば、高性能なリサーチエージェントを開発しているとしましょう。
このエージェントは、単にWeb上の情報を検索するだけでなく、信頼性の高い情報源を見極め、調査結果を要約し、さらには弱点を補いながら出力を最適化する必要があります。
そのためには、プロセスのあらゆるステップを厳密に評価することが不可欠です。情報源の選定精度のテストから、要約のような自由形式のタスクに対して大規模言語モデルを審査役として活用することまで、あらゆる要素を評価対象とし、常に高品質を維持することが求められます。
しかしそれだけでは不十分です。その理由は、エージェントの意思決定プロセス自体も評価の対象となり、無駄な処理や非効率なステップ、無限ループなどを回避するためです。エージェントのワークフローの履歴を分析し、評価ツールを活用してパフォーマンスを測定することで、エージェントの出力とプロセスの両面を改善するための具体的なインサイトを得ることが可能です。
さらに、ワークフローに「オブザーバビリティ(可観測性)」を組み込む方法についても解説致します。
これにより、エージェントの動作をリアルタイムで可視化し、個々のコンポーネントレベルからシステム全体に至るまで、包括的にパフォーマンスを評価できるようになります。そして継続的に改善し続けることが可能になるのです。
それでは、詳しく見ていきましょう!
従来のソフトウェア評価とLLMエージェント評価の違い
LLMモデルの評価 vs LLMアプリケーションの評価
AIシステムを評価する際の指標として、大きく2つに分けられます。
1つ目は LLMモデルの評価 です。
これは、大規模言語モデル(LLM)が特定のタスクをどれだけ正確にこなせるかを測るものです。
例えば、数学の問題を解く、哲学的な質問に答える、コードを生成するといった能力が評価対象となります。
MMLU(Massive Multitask Language Understanding)のようなベンチマークや人間による評価がよく用いられ、LLMの基礎的な能力や強みを明らかにするために役立ちます。
2つ目は LLMアプリケーションの評価 です。
これは、LLMを1つのコンポーネントとして組み込んだアプリケーション全体のパフォーマンスを測定するものです。
単なる言語モデルの性能ではなく、実際のシステムとしてどれだけ価値を提供できるかに焦点を当てます。
この評価には、手動・自動・または実データを元に生成されたデータセットを用い、統合されたシステムの精度や実用性を検証する手法が取られます。
LLMの評価には、モデル単体の能力を見る視点と、実際のアプリケーションとしての有用性を測る視点の両方が重要になります。
LLMアプリケーションのテスト vs 決定論的アプリケーションのテスト
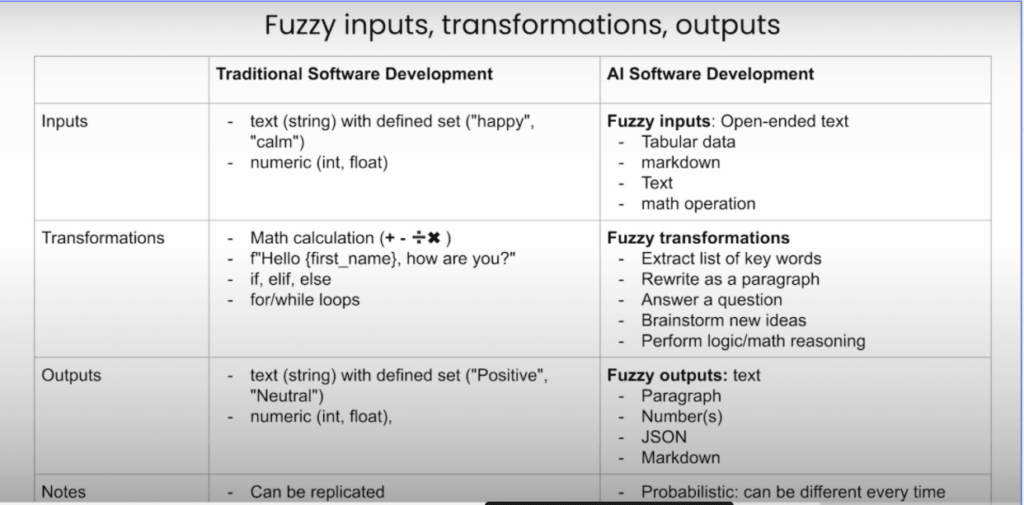
LLMアプリケーション(以下、AIシステム)と従来のソフトウェアでは、テストの方法が根本的に異なります。
従来のソフトウェアは、事前に定義された文字列や数値といった構造化された予測可能な入力を処理します。
一方で、AIシステムは、自由形式のテキストや表データ、Markdownなどの曖昧でオープンエンドな入力を扱うことを得意とします。
また、処理の仕組みにも大きな違いがあります。
従来のソフトウェアは、数学演算、条件分岐、ループ処理など決定論的な変換を行いますが、AIシステムは、キーワード抽出、文章の書き換え、質問応答、推論など確率的で繊細なタスクを処理します。
出力の性質も異なります。
従来のソフトウェアは、事前に定義されたテキストや数値など固定的で再現可能な出力を返しますが、AIシステムは確率的で多様な出力を生成します。出力形式も状況に応じて変化し、通常の文章、JSON、Markdownなど様々です。この違いにより、エンジニアには新たなマインドセットが求められます。
従来のように決定論的な厳密なパイプラインを構築するのではなく、不確実性や変動性を前提としたシステム設計が必要になるのです。

従来のソフトウェアテストは、決定論的な手法に基づいています。
例えば、ユニットテストを用いて個々のコンポーネントの動作を検証し、統合テストでシステム全体が正しく機能することを確認します。
しかし、大規模言語モデル(LLM)の評価には、非決定論的な性質に起因する独自の課題があります。
同じプロンプトを繰り返しても、毎回微妙に異なる出力が生成されるため、従来のような厳格な合格/不合格基準を適用することが難しくなります。
その代わりに、LLMの評価では、関連性・一貫性・全体的なパフォーマンスといった定性的かつオープンエンドな指標が用いられます。
主な評価ポイントには、以下のようなものがあります。
- ハルシネーションの検出(モデルが虚偽の情報を生成していないか)
- 検索結果の関連性(取得したデータがクエリに適しているか)
- 質問応答の正確性(回答がユーザーのニーズを満たしているか)
- 有害性の確認(出力が不適切または有害な言語を含んでいないか)
- 全体的なパフォーマンス目標の達成度
これらの細かな評価基準を考慮することは、信頼性が高く正確で、ユーザーの期待に沿ったAIエージェントを設計するために不可欠です。
エージェントの評価
AIエージェントは、推論・意思決定・行動実行の能力を組み合わせたシステムです。
エージェントは、大規模言語モデル(LLM)を活用し、ユーザーに代わってタスクを実行するソフトウェアベースのシステムです。
効果的なAIエージェントを構築するには、以下の3つの主要な要素を理解することが不可欠です。
・推論(Reasoning):LLMによる情報処理・判断
・ルーティング(Routing):適切なツールやAPIの選択
・行動(Action):APIの呼び出しやコード実行
例えば、大阪への旅行を予約するエージェントを設計するとします。このエージェントは、まず始めに、どのツールやAPIを使用するかを判断し、ユーザーの意図を理解し、必要なリソースを特定しなければなりません。例えば、フライトやホテルを探すために検索APIを呼び出し、追加の質問を通じてクエリを調整し、最終的に旅行の詳細を含む正確でユーザーフレンドリーな回答を提供します。
しかし、この成功は以下のような重要な要素に依存します。
・エージェントは適切なツールを選択したか
・リクエストは正しいパラメータで構成されているか
・ユーザーの希望(場所・日付など)を正確に反映しているか
・最終的な出力は事実に基づき、適切にカスタマイズされているか
課題も存在します。例えば、大阪ではなく広島行きのフライトを予約してしまうような誤りは、ユーザーの信頼を失う原因となります。このような問題を防ぐためには、LLMの出力を評価するだけでなく、各ステップで堅牢な意思決定が行われていることを確認することが重要です。
成功するエージェントを構築するには、戦略的で反復的なアプローチ と厳密な評価 が必要です。
プロンプトやコードに対するわずかな変更でも、予期せぬ影響を引き起こし、一部のユースケースが改善される一方で、他の部分で退行が発生する可能性があります。
この複雑さに対処するためには、以下の点が重要になります。
・代表的なテストケースの維持:重要なシナリオを反映したテストケースを用意し、一貫した評価を実施する。
・システム調整後の再評価(リグレッションテスト):変更の影響を正しく評価し、意図しない退行を防ぐ。
・実際の運用データを活用した評価:ユーザーとの実際の対話データを取り入れ、現実的なテストを実施する。
エージェントは従来のソフトウェアとは異なり、本質的に非決定論的であり、問題解決のために複数のルートを取ることが可能です。そのため、あるシナリオで優れたパフォーマンスを発揮しても、別のシナリオでは性能が低下する可能性があります。これを防ぐために、多様なユースケースを網羅した一貫性のあるテストセットを確立することが重要です。
これらのテストには、実際の運用データやユーザーとのやり取りを含めることで、より現実的な評価が可能になります。プロンプトの調整やツールの改良などを通じた反復的なテストと改善が、退行の解決とテスト範囲の拡大には不可欠なのです。
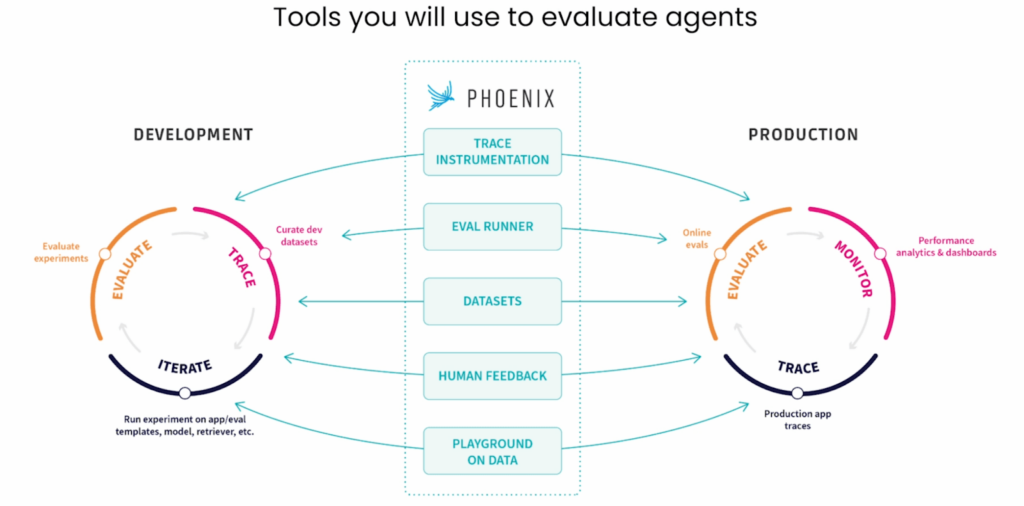
このプロセスを支援するために、以下のツールの活用をお勧めします。
トレース計測:
エージェントの動作を理解し、挙動を分析するためのツール。
評価ランナー:
実験やフィードバックを集め、エージェントの性能を評価するツール。
データセット:
実際の運用環境での注釈を記録し、評価に活用するデータセット。プロンプトプレイグラウンド:
データ駆動型の反復を行い、エージェントの精度向上を図るためのツール。
エージェントの観察 – トレース
成功するAIエージェントを構築するには、可観測性(Observability)をマスターすることが重要 です。
可観測性とは、アプリケーションのあらゆる層に対して完全な可視性を確保するための基本的なソフトウェア概念です。
AIエンジニアがLLM(大規模言語モデル)を扱う際には、以下のような重要なメトリクスを追跡することが求められます。
・プロンプト(LLMへの入力)
・レスポンス(LLMの出力)
・トークン使用量(コストや制約の管理)
・LLMへの呼び出しの流れ(どのようにリクエストが処理されるか)
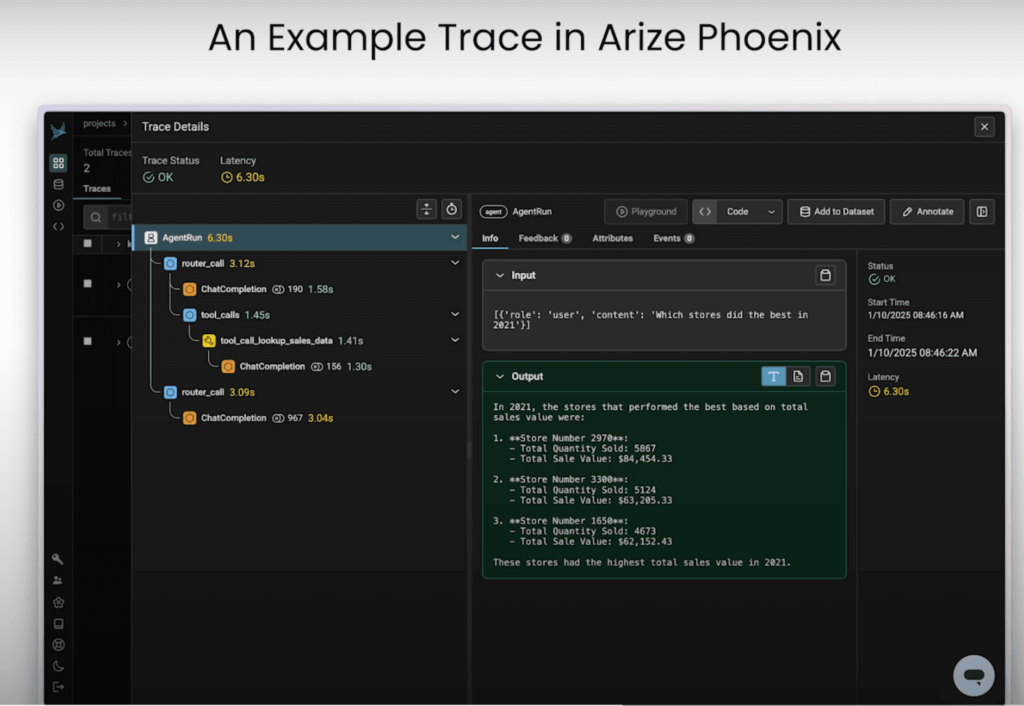
可観測性の中心には、トレース(Trace)とスパン(Span) の2つの基本的な要素があります。
トレースとは、アプリケーションの全体の流れを表すものです。
最初の入力から最終的な出力までのエンドツーエンドの実行プロセスを示します。
スパンは、トレースを構成する個々のステップです。
例えば、LLMとのやり取り、データベース検索、API呼び出しといったような処理をスパンとして分解できます。
スパンは階層的に構造化されており、互いにネストすることで、それぞれの関連性や依存関係を明確に示します。
例えば、LLMの呼び出し、ツールの統合、論理的なワークフローの各ステップなどがスパンとして表現されることが多くあります。
スパンを組み合わせることで、包括的なトレース階層が形成され、エージェントの内部処理を可視化することが可能になります。
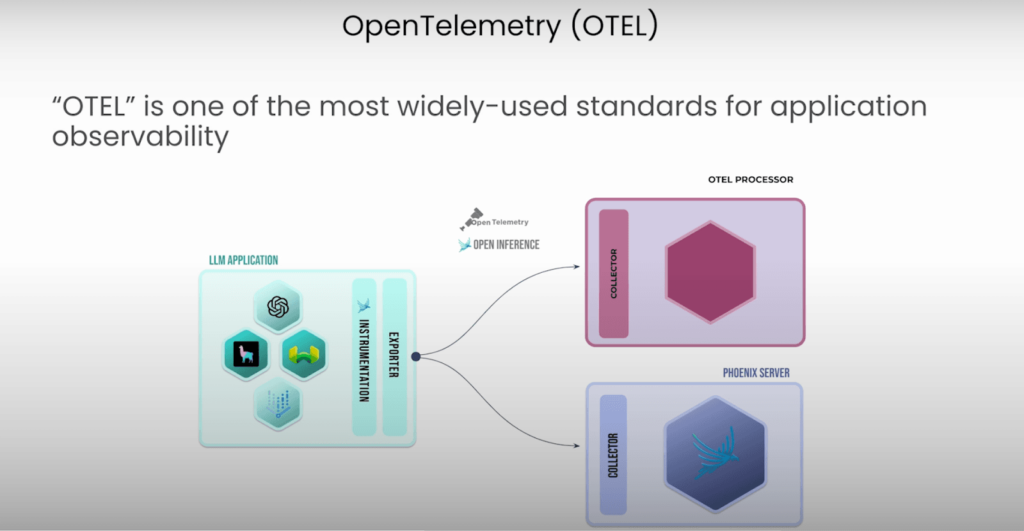
このトレース構造は、OpenTelemetry(OTEL) を使用して実装されることが一般的です。
OTELは、アプリケーション全体の可観測性を向上させるために広く採用されているフレームワークであり、以下のような利点があります。
・トレースやスパンの収集・可視化を標準化
・AIエンジニアだけでなく、すべての開発者にとって有用
・インスツルメンテーション(可観測性のフックをコードに埋め込むプロセス)が可能
・リアルタイムでのパフォーマンス監視とデバッグ支援
OTELを活用することで、単なるデータ収集を超えて、エージェントの振る舞いやパフォーマンスの最適化が可能になります。
なぜ可観測性が重要なのか?
可観測性は、AIアプリケーションの構築とスケーリングにおいて重要な役割を果たします。
開発初期の段階では、アプリケーションの挙動を視覚的に追跡できるため、無数のprint文やログを解析するよりも、はるかに効率的にデバッグを行うことができます。
アプリケーションが成長し、本番環境やテスト環境に移行すると、可観測性の重要性はさらに増します。
可観測性によって、アプリケーションへのすべての呼び出しや受け取った入力が詳細に記録され、それらを基に異なる実行環境でのパフォーマンスを監視するための豊富なデータベースが構築されます。
このデータは、アプリケーションの複数の反復を通じたパフォーマンスを分析するための基盤となります。例えば、Phoenixのようなツールを活用すれば、データをエクスポートし、より深い洞察を得ることが可能になります。
最終的に、可観測性は大規模言語モデル(LLM)の予測不可能な挙動を理解し、管理するための鍵となります。
AIエージェントの動作を継続的に監視・評価することで、現実のシナリオに適した形で最適化し、成功へと導くことができるのです。
評価の設定 – 評価の種類について

AIシステムを評価するための主な手法には、以下があります。
・コードベースの評価
・LLMとジャッジによる評価
・人間によるアノテーション
この中でも、コードベースの評価は最もシンプルで、従来のソフトウェアテストや統合評価に最も近い方法とされています。
コードベースの評価では、アプリケーションの出力に対してコードを実行し、特定の基準に基づいて正当性を検証します。
例えば、出力が特定の正規表現(regex)に一致するかを確認し、応答が数値のみで構成されているか、英数字を含まないかをチェックできます。
また、出力がJSON形式に準拠しているかを検証したり、特定のキーワードを含まないようにフィルタリングすることも可能です(例:チャットボットが競合他社の名前を出さないようにするなど)。
さらに、正解データ(教師データ)が利用できる場合、アプリケーションの出力と期待される出力を直接比較できます。
この比較では、単純な文字列の一致だけでなく、文字列の類似度やコサイン類似度などの高度なメトリクスを用いて、意味的な一致度を評価することも可能です。
この評価手法は、AIシステムの信頼性を確保し、その挙動を制御するうえで特に効果的です。そのため、堅牢なモデルを開発するAIエンジニアにとって、非常に有用なツールとなります。
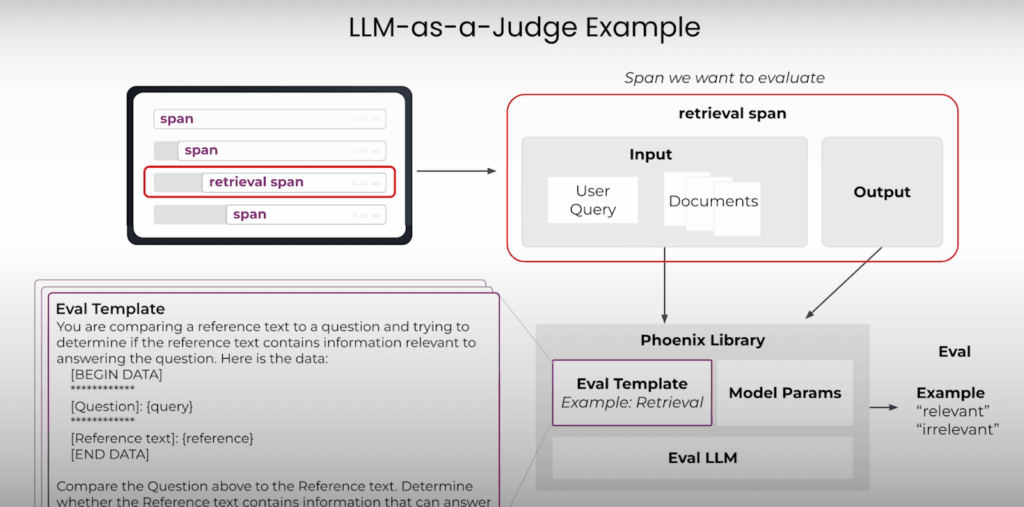
「LLM-as-a-Judge」(LLMを審査員として用いる評価手法)は、注目を集めているAIシステムの評価方法です。
この手法では、別の大規模言語モデル(LLM)を活用し、アプリケーションの出力を評価します。プロセスは次のように進行します。
まず、システムから重要な入力と出力を取得し、それを基に評価用のプロンプトを作成します。
このプロンプトを「審査員」として機能するLLMに送信し、事前に定義された基準に基づいてラベル付けや判断を行います。
例えば、取得したドキュメントが特定のクエリに関連しているかどうかを評価することができます。
リトリーバル強化生成(RAG)システムでは、この手法を使って、取得したドキュメントがユーザーのクエリにどれだけ適合しているかを評価することが可能です。
クエリと取得したドキュメントを評価用テンプレートに組み込み、それをLLMに渡します。LLMは「これらのドキュメントはユーザーの質問に関連していますか?」という問いに対して、「関連あり」や「関連なし」といったラベルを返します。このようにして、大規模かつ定量・定性的な評価を行う仕組みとなっています。
この評価手法で意味のある結果を得るためには、人間の判断に近い精度を持つ高性能モデル(例えば、GPT-4やClaude 3.5)が必要です。
しかし、それでも完全な正確性を保証することはできず、一定の誤差が発生する可能性があります。この問題を軽減するために、エンジニアはプロンプトを慎重に調整し、曖昧なスコアリングではなく「正しい」「誤り」のような明確な分類ラベルを使用することが推奨されます。LLMは数値的な尺度の解釈が一貫しないことが多いためです。
最終的に、LLM-as-a-Judgeは大規模な評価を実施するための強力な手法ですが、信頼できる結果を得るためには、慎重な設定と調整が不可欠です。
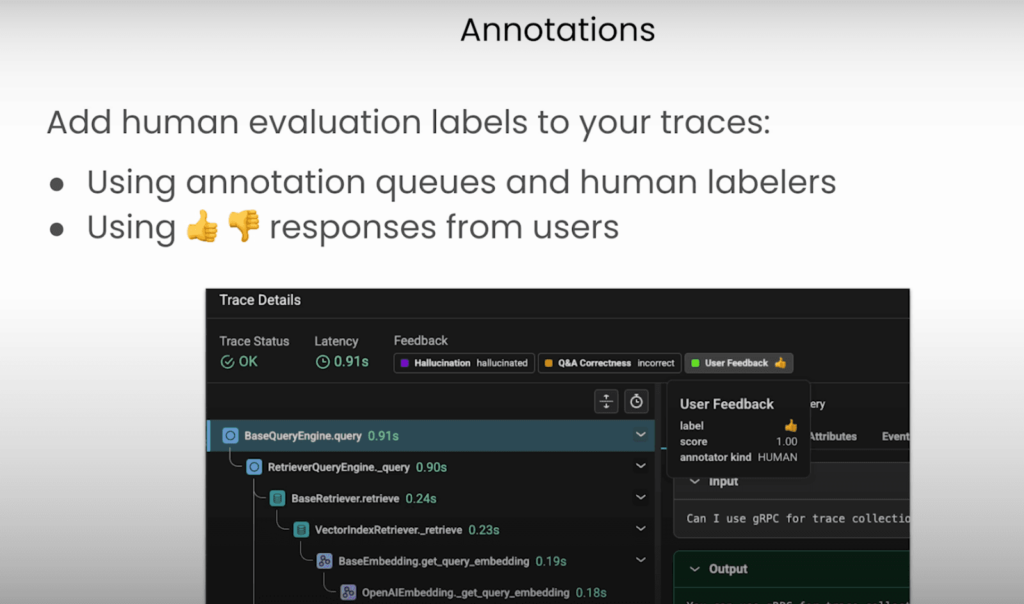
AIアプリケーションを改善するための強力な評価手法の一つに、アノテーション(注釈付け)や人間によるラベル付けがあります。
Phoenixやその他の可観測性プラットフォームを活用することで、アプリケーションの出力を集めたアノテーションキューを作成できます。このキューをもとに、人間のラベラーが順番に出力を確認し、フィードバックを付与したり、応答の品質を評価したりします。
また、エンドユーザーから直接フィードバックを得る方法もあります。例えば、アプリケーションに「いいね」「よくないね」といった評価機能を組み込むことで、ユーザーが簡単に意見を伝えられるようになります。
このようなアプローチは、モデルの実際のパフォーマンスに関する現実的な洞察を提供し、ユーザーからの評価に基づいてAIアプリケーションを反復的に改善することを可能にします。
結論
AIエージェントの開発ライフサイクルに可観測性を統合することは、単なる技術的な向上ではなく、何百人、何千人ものユーザーが利用する本番環境へスケールさせるために不可欠な要素です。
開発初期から可観測性を導入することで、開発者は異常を早期に検出し、根本原因の分析を行い、実環境に最適化されたアプリケーションの継続的な改善が可能になります。
このプロセスは、透明性と信頼性を保証することで、ユーザーの信頼を高め、規制遵守にも寄与します。さらに、可観測性を導入した組織は、問題解決までの時間を短縮し、ROI(投資収益率)の向上を報告しています。業界調査によると、可観測性フレームワークを活用したAI導入では、最大28%のビジネス価値向上が見られたという結果もあります。
最終的に、可観測性はAI開発を反復的でユーザーに寄り添ったプロセスへと変革します。
このアプローチにより、リスクを軽減しつつ、イノベーションの加速を実現できるのです。
もしお使いのAIエージェントのパフォーマンスに課題を感じている場合は、ぜひお気軽にご相談ください。