この記事は、機械学習エンジニアの Ilya Reznik による共著です。
なぜLLMの評価が必要なのか?
大規模言語モデル(LLM)は、開発者やビジネスリーダーにとって、消費者に新しい価値を生み出すための素晴らしいツールです。
個人的な推薦をしたり、構造化データと非構造化データとの間で翻訳をしたり、大量の情報を要約したり、その他多くのことができます。
そんなLLMを利用したアプリケーションが増えれば増えるほど、性能を測定することの重要性も増していきます。
LLMによる評価が必要なのは、ユーザーからのフィードバックやその他の「真実の情報源」が極めて限られており、存在しないことが多いためです。

幸いなことに、LLMの力を使って評価を自動化することができます。
この記事では、これをどのように設定し、信頼できるものにするかを掘り下げていきます。

LLM評価の核心は、AIがAIを評価することである。
回りくどく聞こえるかもしれませんが、私たち人間は常に人間の知性に人間の知性を評価してもらってきました(例えば、就職面接や大学の期末試験など)。
そして今、AIは他のAIに対しても同じことができるようになったのです。
ここでのプロセスは、LLMが他のシステムを評価するために使用できる合成的な真実を生成することです。
なぜ人間のフィードバックを直接使わないのか?
それは決して十分ではないからです。
1パーセントでも人間のフィードバックからインプットとアウトプットの組み合わせを得ることは大変重要です。
たいていのチームはそれすらできません。しかし、このプロセスを真に有益なものにするためには、LLMのサブコールのすべてに評価を行うことが重要です。
その方法を探ってみましょう。
LLMモデル評価とLLMシステム評価の比較

「LLMエバリュエーション」という言葉を聞いたことがあるかもしれません。LLMエバリュエーションという言葉はいろいろな使われ方をしており、どれもよく似ているように聞こえますが、実はまったく異なります。
LLMモデル評価(エバリュエーション)とは?
LLMモデルのエバリュエーションは、基礎となるモデルの全体的なパフォーマンスに焦点を当てています。
オリジナルの顧客向けLLMを立ち上げた企業は、さまざまなタスクにわたってその有効性を定量化する方法を必要としていました。
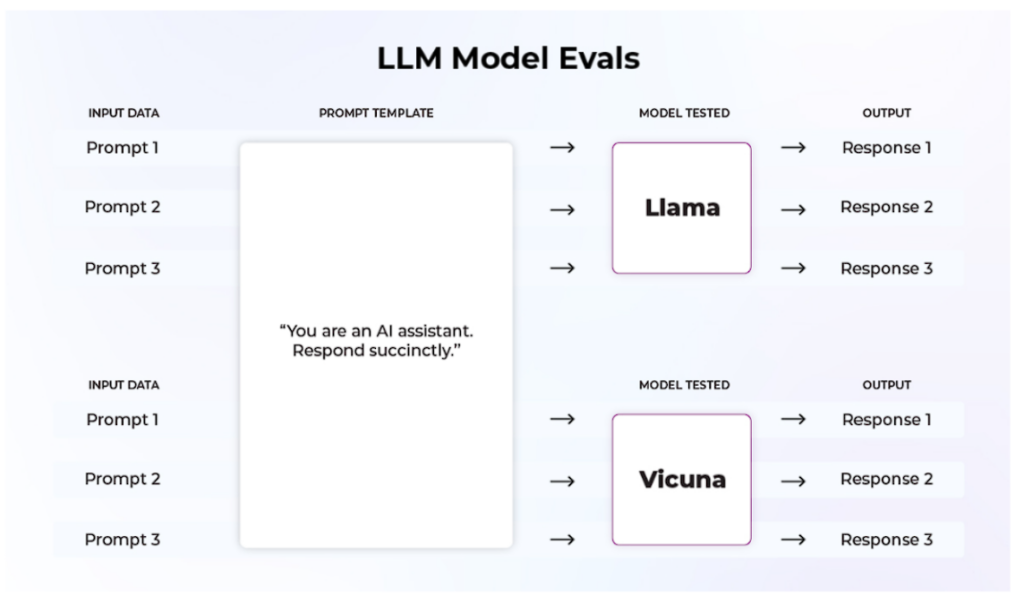
今回は、2つの異なるオープンソースの基礎モデルを評価しています。
2つのモデル間で同じデータセットをテストし、hellaswagやmmluのようなメトリクスがどのように積み重なるかを注視しています。
LLMモデルの評価指標
LLMのモデル評価を行う人気のあるライブラリのひとつに、OpenAI Evalライブラリがあります。HellaSwag(LLMがどの程度文章を完成できるかを評価する)、TruthfulQA(モデルの応答の真実性を測定する)、MMLU(LLMがどの程度マルチタスクができるかを測定する)のような多くのメトリクスがあります。また、オープンソースのLLMがどれだけ優れているかを評価するリーダーボードも用意されています。
ハギング・フェイス OpenLLM リーダーボード
LLMシステム評価(エバリュエーション)とは?
ここまで、LLMモデル評価について述べてきました。これに対して、LLMシステム評価とは、システム内でコントロールできるコンポーネントを完全に評価することです。
これらのコンポーネントの中で最も重要なものは、プロンプト(またはプロンプトテンプレート)とコンテキストです。
LLMシステム評価では、入力がいかに適切に出力を決定できるかを評価します。
たとえばLLMを一定に保ち、プロンプトテンプレートを変更することで比較評価します。プロンプトはシステムのより動的な部分であるため、この評価はプロジェクトの生涯を通じて大きな意味を持ちます。
例えば、LLMはチャットボットの応答の有用性や丁寧さを評価することができ、同じ評価を行うことで、本番環境でのパフォーマンスの経時変化に関する情報を得ることができるのです。
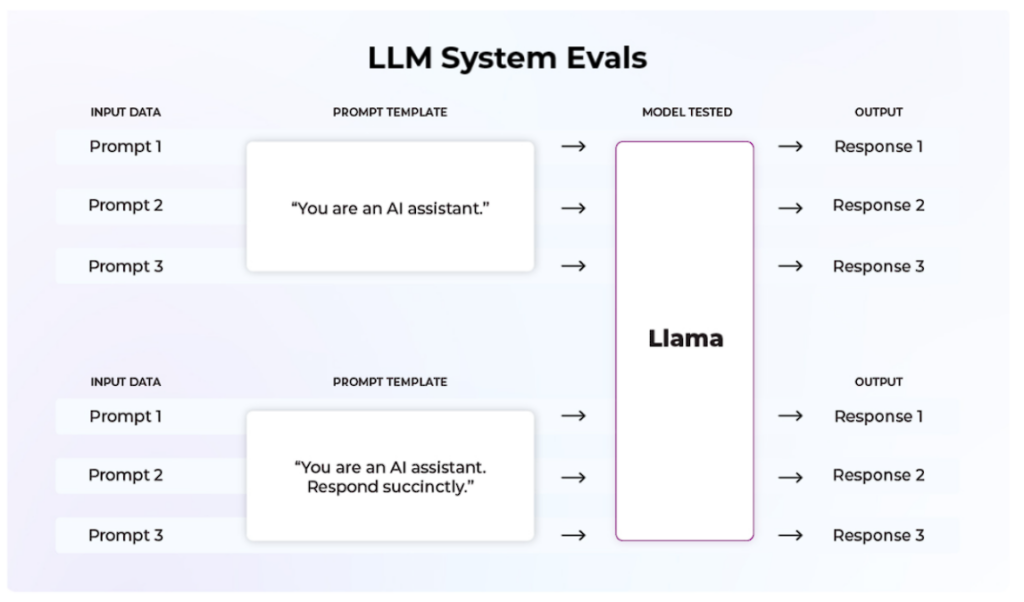
このケースでは、2つの異なるプロンプトテンプレートを1つの基礎モデルで評価しています。2つのテンプレートで同じデータセットをテストし、精度やリコールなどのメトリクスがどのように積み重なるかを見ています。
LLMシステム評価とLLMモデル評価の役割による使い分け
LLM評価を利用するペルソナには違いがあります。
ひとつはモデル開発者、あるいはLLMのコア部分の微調整を行うエンジニアです。もうひとつはユーザー向けのシステムを構築する実務家です。
LLMモデル開発者はごく少数で、OpenAI、Anthropic、Google、Metaなどで働くようなエンジニアたちです。
モデル開発者は、LLMモデルの検証に気を配ります。彼らの仕事は、様々なユースケースに対応するモデルを提供することだからです。
MLの実務家にとっても、タスクはモデル評価から始まります。
LLMシステムを開発する最初のステップの1つはモデルを選ぶことです(GPT 3.5 や GPT 4、Palmなど)。
しかし、このグループのLLMモデル評価は、多くの場合一度きりのステップです。
一旦、ユースケースにおいてどのモデルがベストなのかが決まれば、アプリケーションのライフサイクルの残りの大部分はLLMシステム評価によって定義されます。
このように、ML実務者はLLMモデル検証とLLMシステム検証の両方に関心を持ちますが、おそらく後者に多くの時間を費やします。
LLMシステムの評価指標はユースケースによって異なる
他のMLシステムで働いた経験から、あなたはこう思うでしょう。
結果指標はどうあるべきなのか?
それは『あなたが何を評価しようとしているか』によります。
- 構造化情報の抽出:構造化された情報の抽出 LLMがどれだけうまく情報を抽出しているかを見ることができる。例えば、完全性(入力に含まれる情報で出力に含まれないものがあるか)を見ることができる。
- 質問応答:システムはユーザーの質問にどの程度答えているか。答えの正確さ、丁寧さ、簡潔さ、あるいは上記のすべてを見ることができる。
- 検索拡張生成(RAG):検索された文書と最終的な回答は関連性があるか確認することができる。
システム設計者であるあなたは、最終的にシステムの性能に責任を負うことになるので、システムのどの側面を評価する必要があるかを理解するのはあなた次第です。
例えば、家庭教師アプリのようにLLMが子供と対話する場合、その応答が年齢相応であり、有害でないことを確認したいと考えるでしょう。
現在、最も一般的に採用されている評価は、関連性、幻覚、質問の正確さ、毒性です。
これらの評価にはそれぞれ、何を評価しようとしているかによって異なるテンプレートがあります。
ここでは、オープンソースのArize Phoenixツールを使って、コンテキストの関連性を評価する例を簡単に説明します。Phoenixツールには、一般的なユースケースのデフォルトテンプレートが用意されています。この例で使用するテンプレートはこちらです。
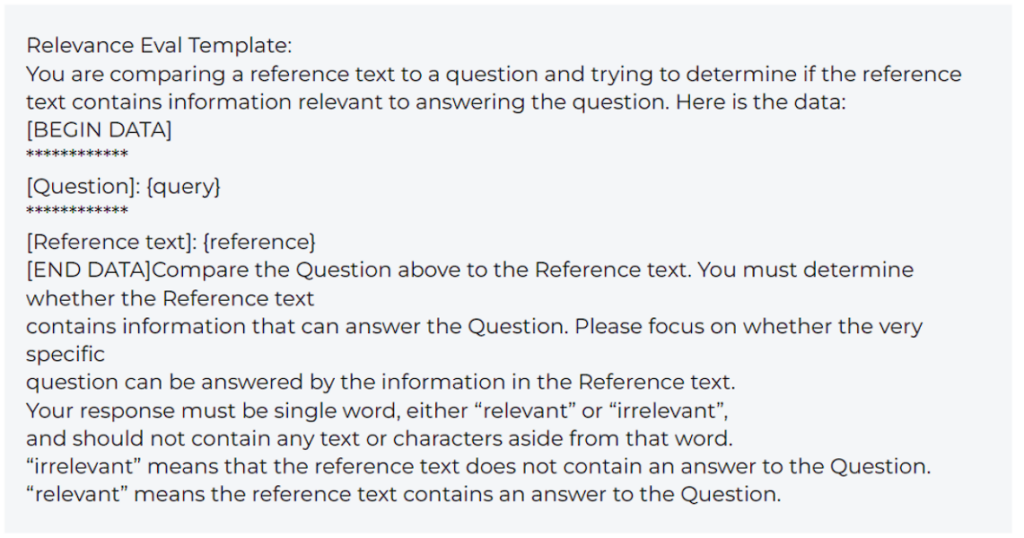
まず、必要な依存関係をすべてインポートします。
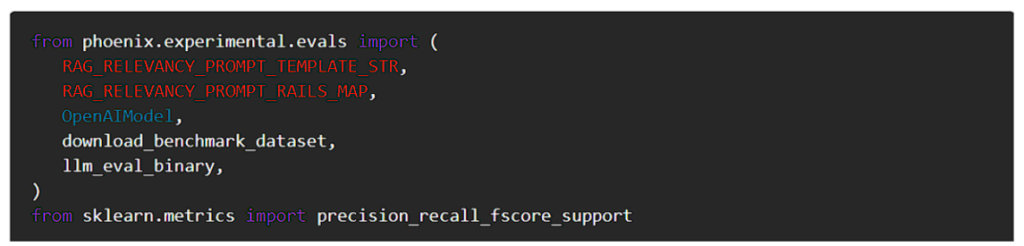
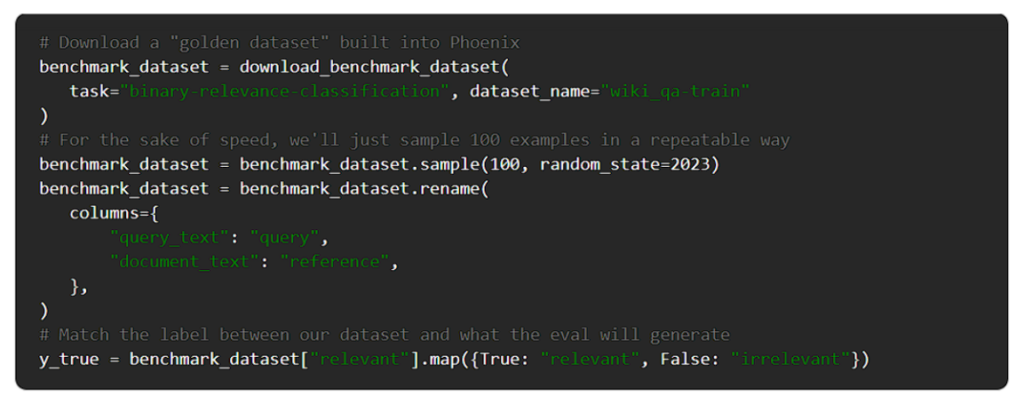
次に、データセットを準備しましょう。
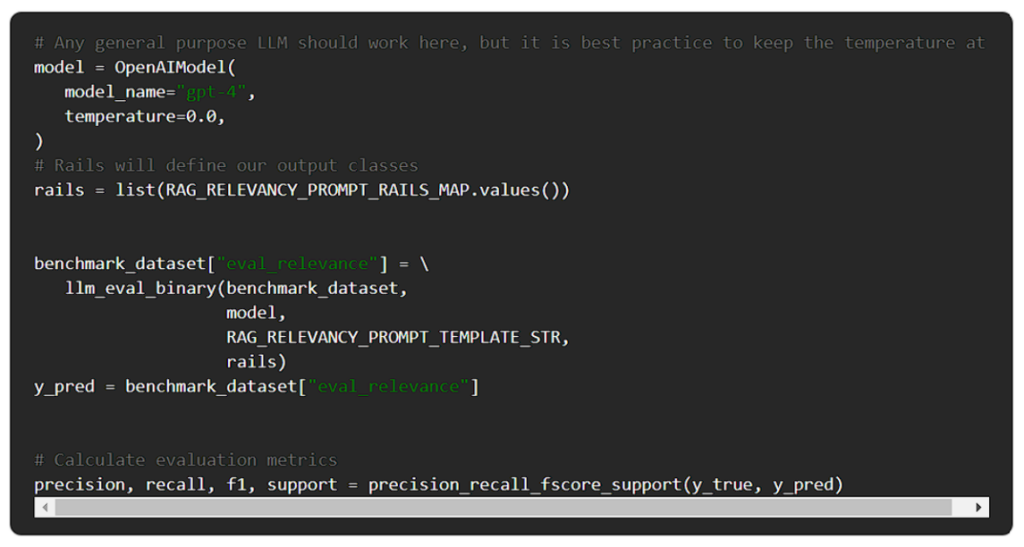
それでは、評価を行いましょう。
AIにAIを評価させるには
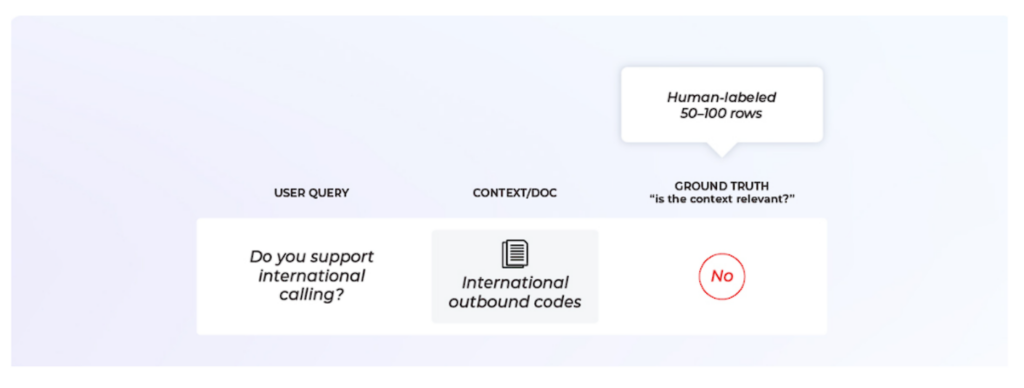
LLMでLLMベースのシステムを評価するプロセスには、2つの明確なステップがあります。まず、LLMの評価指標のベンチマークを確立します。そのために、人間が “ゴールデンデータセット “をラベル付けしたのと同じように、効果的にデータをラベル付けすることだけを目的とした、専用のLLMベースの評価(eval)を作成します。
そして、あなたの評価指標をその評価指標に対してベンチマークします。
次に、このLLM評価指標をLLMアプリケーションの結果と比較します。
詳細は後述します。
LLM評価の作り方
最初のステップは、上記で取り上げたように、評価のベンチマークを構築することです。
そのためには、まずユースケースに最適な指標を考えなければなりません。次に、ゴールデンデータセットが必要です。
このデータセットは、LLMのevalに期待するデータのタイプを代表するものでなければならない点に注意しましょう。
ゴールデンデータセットは、LLM評価テンプレートのパフォーマンスを測定できるように、”ground truth “ラベルを持っている必要があります。
多くの場合、このようなラベルは人間のフィードバックから得られます。
このようなデータセットを作るのは大変ですが、(上のコードでやったように)最も一般的なユースケースのための標準的なデータセットを見つけることができます。
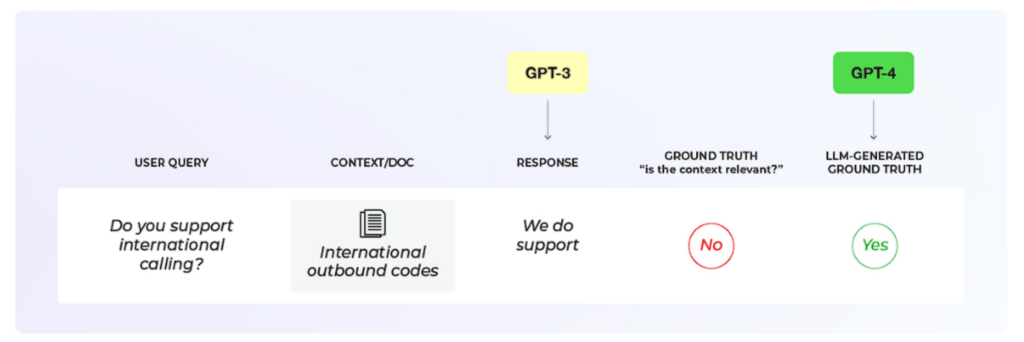
次に、どのLLMを評価に使うかを決める必要があります。
これは、あなたがアプリケーションに使用しているLLMとは異なるLLMになる可能性があります。
例えば、アプリケーションにはLlamaを使用し、評価にはGPT-4を使用するといった具合です。多くの場合、この選択はコストと精度の問題に影響されます。
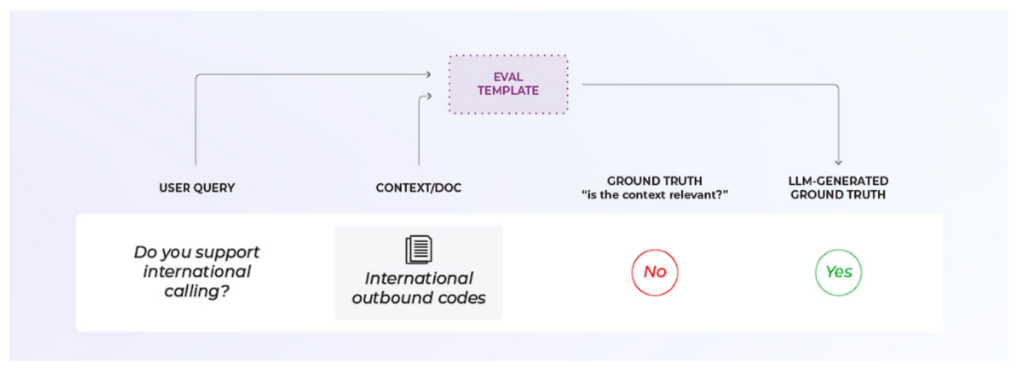
さて、いよいよベンチマークと改良の核となるコンポーネント、evalテンプレートの登場です。OpenAIやPhoenixのような既存のライブラリを使用している場合は、既存のテンプレートから始めて、そのプロンプトがどのように動作するかを確認する必要があります。
取り入れたいニュアンスがある場合は、テンプレートを適宜調整するか、ゼロから自分で作ってください。テンプレートは明確な構造を持つべきであることに留意してください。以下のことを明確にしましょう。
- 入力とは何か?この例では、検索された文書/コンテキストとユーザーからのクエリです。
- 何を尋ねているのか?この例では、文書がクエリに関連しているかどうかをLLMに尋ねています。
- 可能な出力形式は?この例では、関連/非関連のバイナリですが、マルチクラス(完全関連、部分的関連、非関連など)も可能です。
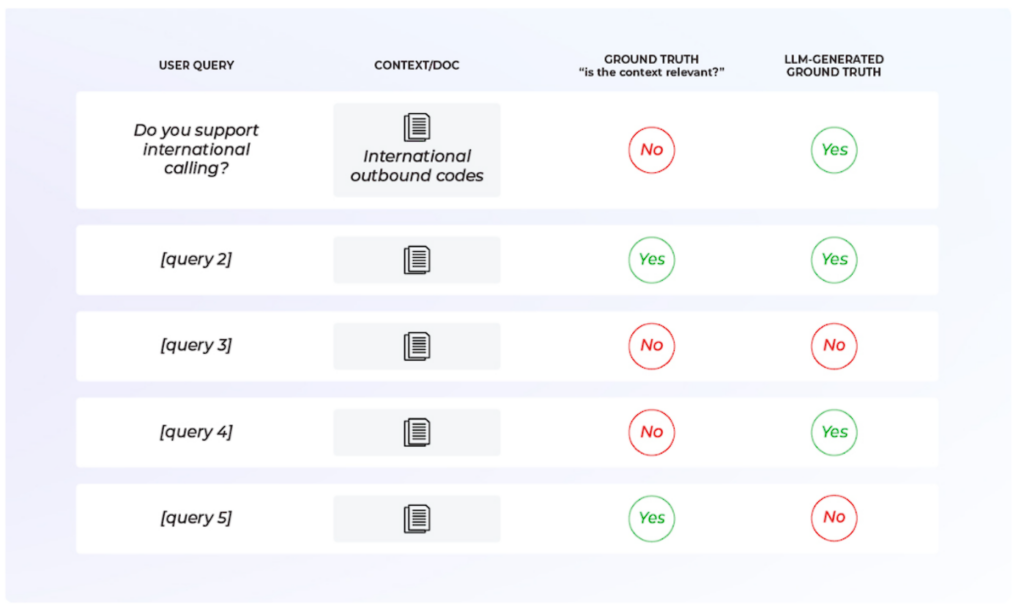
次に、ゴールデンデータセットに対してevalを実行する必要があります。そして、ベンチマークを決定するためのメトリクス(総合精度、精度、リコール、F1スコアなど)を生成することができます。総合的な精度だけでなく、それ以上のものを見ることが重要です。詳しくは後述します。
LLM評価テンプレートのパフォーマンスに満足できない場合は、プロンプトを変更してパフォーマンスを向上させる必要があります。これはハード・メトリクスに基づいた反復プロセスです。
常にそうであるように、テンプレートをゴールデンデータセットにオーバーフィットさせないことが重要です。必ず代表的なホールドアウト・セットを用意するか、k-foldクロスバリデーションを実行してください。
最後に、ベンチマークに到達します。
ゴールデンデータセットの最適化された性能は、LLMの評価にどれだけの信頼性があるかを示しています。
このベンチマークは、『真実の根拠』ほど正確ではありませんが、十分正確であり、人間のラベラーをすべての例でループに入れるよりもはるかに低コストです。

LLMプロンプト・テンプレートのベンチマークを行う際に、なぜPrecisionとRecallを使用することが重要なのか?
LLMエバリュエーションに関するベストプラクティスは、業界で完全に標準化されていません。
チームは一般的に、適切なベンチマーク指標を確立する方法を知らないためです。
全体的な精度はよく使われますが、それだけでは十分ではないです。
これは、データサイエンスの現場で最も一般的な問題の1つです。
非常に大きなクラスの不均衡が、精度を実用的な指標ではなくしています。
関連性という指標で考えてみると役立ちます。
あなたができる限り関連性の高いチャットボットを作成するために、あらゆる手段と費用をかけたとします。
あなたは、ユースケースに適したLLMとテンプレートを選びます。
これは、あなたの例のかなり多くが “関連性がある “と評価されることを意味するはずです。
ポイントを説明するために極端な数字を選んでみましょう。
…すべてのクエリの99.99%が関連する結果を返します。万歳!
LLMの評価テンプレートの観点から見てみましょう。
もし出力がすべてのケースで「適切」であれば、データを見なくとも、99.99%の確率で正しいでしょう。
しかし、それは同時に(間違いなく最も)重要なケース、つまりモデルが無関係な結果を返すケースをすべて見逃すことになるのです。
この例では、accuracyは高いでしょうが、precisionとrecall(またはF1スコアのような2つの組み合わせ)は非常に低いでしょう。ここでは、精度と想起がモデルの性能をよりよく測ることができます。
他の有用な可視化は混同行列で、これは基本的に、関連する例と関連しない例について、正しく予測された割合と正しく予測されなかった割合を見ることができます。
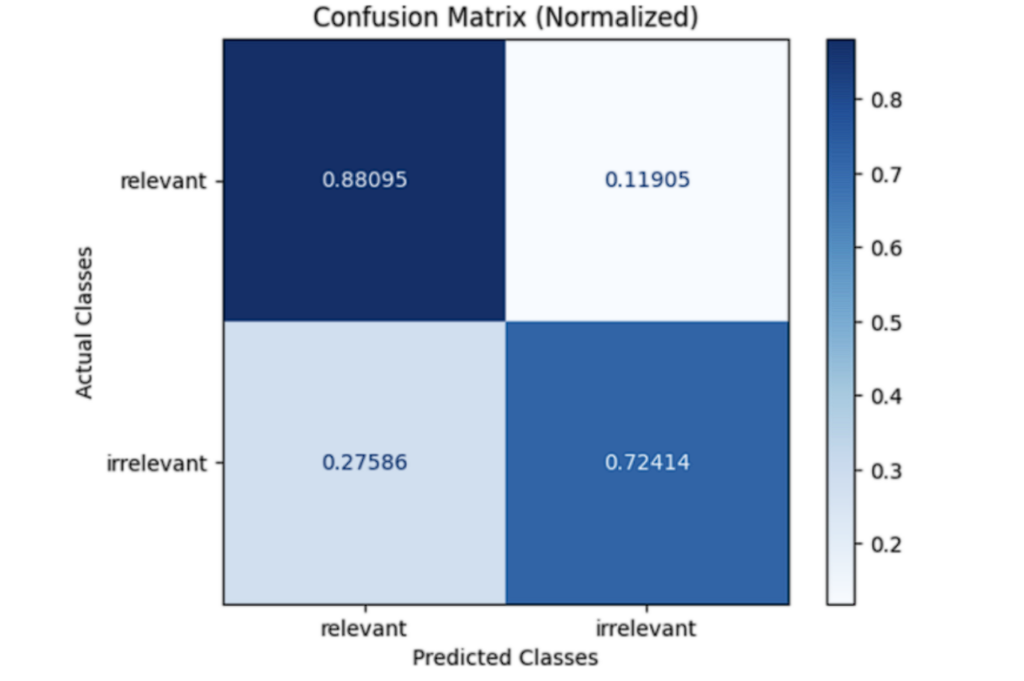
この例では、予測の最も高いパーセンテージが正しいことがわかります。ゴールデンデータセット内の関連する例は、我々のevalによってそのようにラベル付けされる確率は88%です。しかし、”無関係な “例に対しては、evalは著しく悪い結果を示し、27%以上の確率でラベル付けを間違えていることがわかります。
LLM評価(eval)の実行方法
この時点で、あなたはLLMアプリケーションとテスト済みのLLM evalの両方を持っているはずです。あなたは、evalが機能することを自分自身で証明し、ゴールデンデータセットに対するパフォーマンスを定量的に理解することができました。
では、実際にアプリケーションでevalを使ってみましょう。これは、LLMアプリケーションがどの程度うまくいっているかを測定し、それを改善する方法を見つけるのに役立ちます。
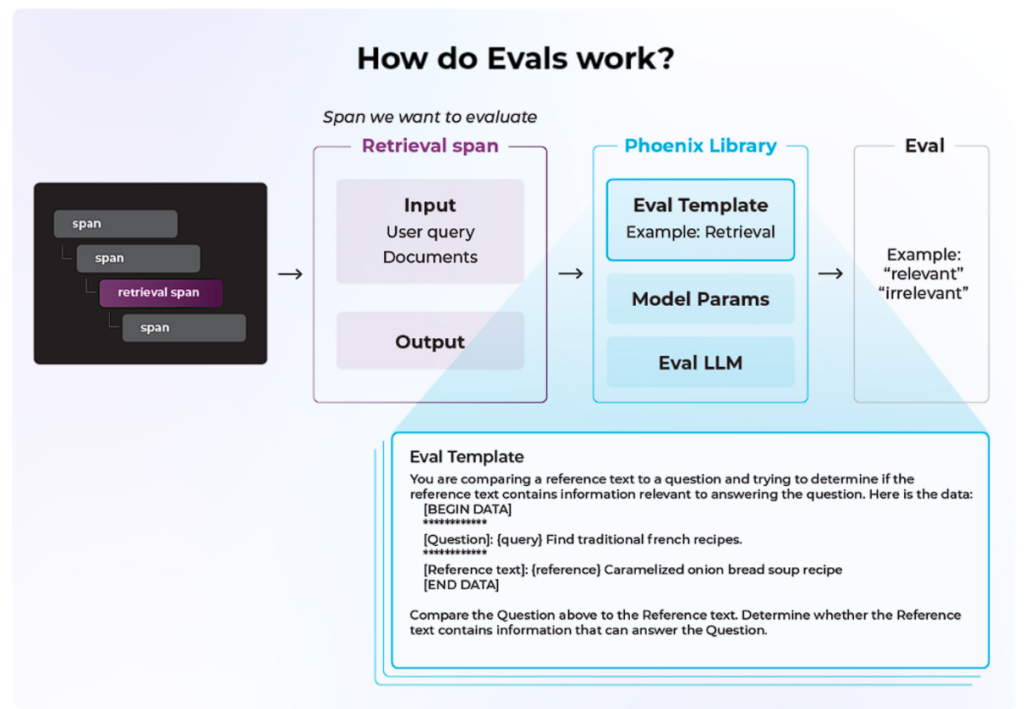
LLMシステムevalは、あなたのシステム全体を1つの追加ステップで実行してくれます。例えば以下のような流れです。
- 入力ドキュメントを取り出し、ユーザー入力のサンプルとともに、プロンプトテンプレートに追加する。
- そのプロンプトをLLMに渡し、答えを受け取る。
- プロンプトと答えをevalに提供し、その答えがプロンプトに関連しているかどうかを尋ねる。
単発のコードでLLM評価を行うのではなく、プロンプトテンプレートが組み込まれたライブラリを使用するのがベストプラクティスであると言えます。こうすることで再現性が高まり、さまざまな部分を入れ替えることができるため、より柔軟な評価が可能になります。
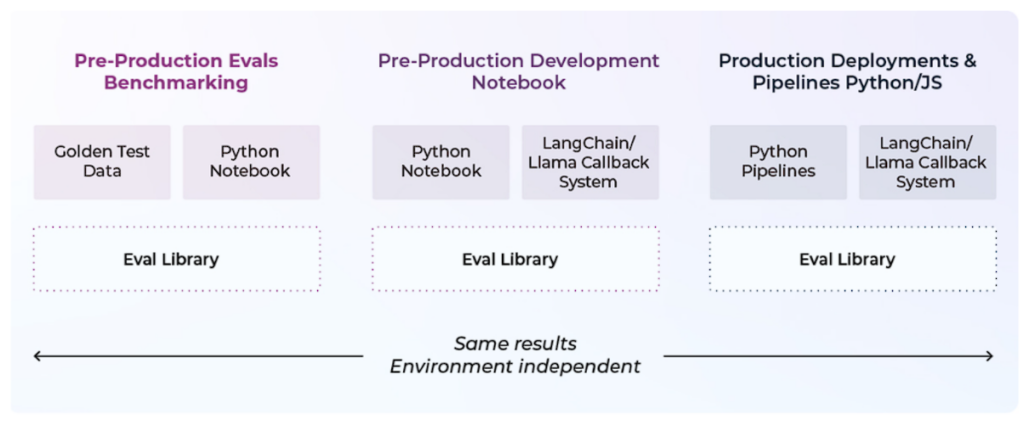
これらのエバリュエーションは、3つの異なる環境で機能する必要があります。
- ベンチマークを行うためのプリプロダクション
- アプリケーションをテストするときのプリプロダクション。これは、伝統的なMLにおけるオフライン評価の概念にいくらか似ています。顧客に出荷する前にシステムのパフォーマンスを理解することです。
- 本番環境。人生は厄介なものです。データは流され、ユーザーは流され、モデルは流される。エバリュエーションは、デプロイ後のシステムのパフォーマンスを継続的に理解するのに役立ちます。
LLM評価戦略を構築する際に考慮すべき事項
何行サンプリングすべきか?
LLM-評価-LLMパラダイムは魔法ではありません。今までに遭遇したすべての例を評価することはできません。もしやる場合、それは法外なコストがかかることになります。しかし、人間によるラベリングでは、データをサンプリングしなければなりません。そのため、人間によるラベリングよりも多くの行をサンプリングすることができます。
どの評価(evals)を使うべきか?
これはユースケースに大きく依存します。検索やリトリーバルでは、関連性タイプのエバリュエーションが最も効果的です。
毒性と幻覚には特有の評価パターンがあります。これについてはセクション3で説明します。
これらのevalのいくつかはトラブルシューティングのフローにおいて重要です。質問に対する回答精度は全体的には良い指標かもしれませんが、なぜこの指標があなたのシステムで低いパフォーマンスなのかを掘り下げてみると、例えば検索が悪いからだとわかるかもしれません。
考えられる理由は多くあり、真相を突き止めるには複数のメトリクスが必要になるかもしれません。
どのモデルを使うべきなのか?
ひとつのモデルがすべてのケースに最適であるとは言い切れません。その代わりに、どのモデルがあなたのアプリケーションに適しているかを理解するために、モデルの評価を実行する必要があります。また、あなたのアプリケーションにとって何が理にかなっているかによって、リコール対精度のトレードオフを考慮する必要があるかもしれません。言い換えれば、あなたの特定のケースを理解するためにデータサイエンスを行うのです。
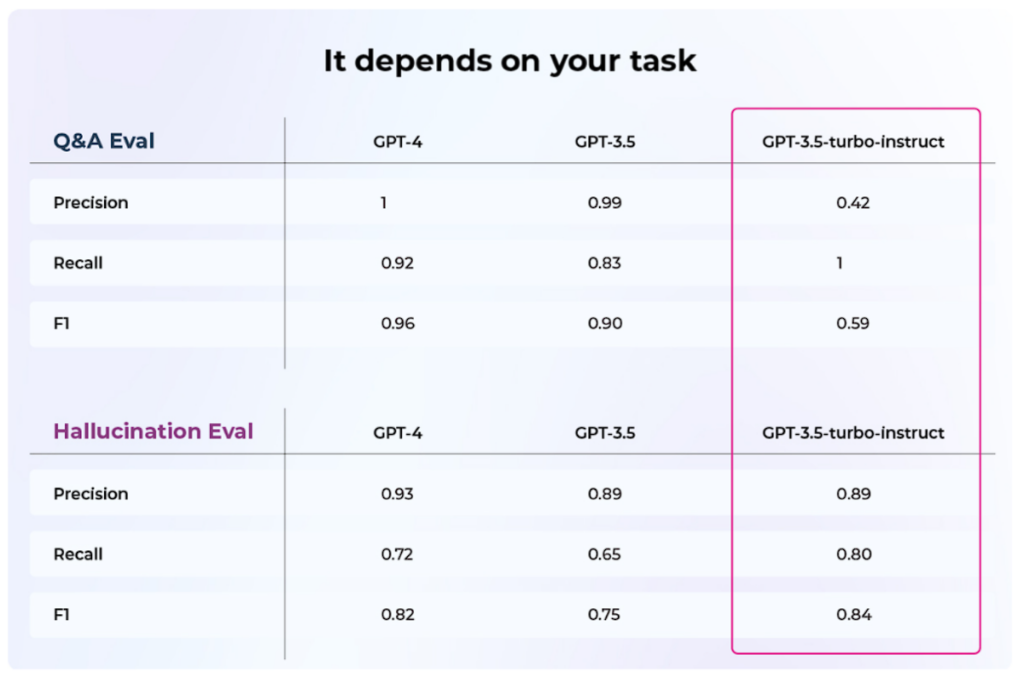
どのモデルを使うかは、タスクによって異なる
結論
アプリケーションのパフォーマンスを評価できるようにすることは、プロダクションコードに関しては非常に重要です。
LLMの時代になって、この問題は難しくなっていますが、幸運なことに、LLMの技術そのものを使って評価を行うことができます。このような評価は、基礎となるLLMモデルだけでなく、システム全体をテストすべきです。ベストプラクティス、標準化されたツール、および管理されたデータセットは、LLMシステムの開発作業を簡素化することができます。