現在、LLMが大流行しており、GPT-4のようなクローズドソースのモデルのAPIは、AIの力を活用することをかつてないほど容易にしています。
しかし、多くの規制産業にとって、これらのクローズドなソースモデルは選択肢とはなりません。幸いなことに、Llama 3、Mistral、Falconのようなオープンソースの代替モデルが多数あり、これらの業界もLLMの流行に乗ることができます。
これらのオープンソースのモデルは、クローズドソースのモデルと同様に強力であり、カスタマイズが容易であるという利点もあります。
オープンソースのモデルは実行可能な選択肢ではありますが、デプロイメント、サービス提供、監視を自分で行う必要があります。
もしあなたがAI分野の初心者なら、これは大変な作業に思えるかもしれませんが、心配ご無用です。
この記事では、UbiOpsとArizeを活用してLLMアプリケーションを簡単にデプロイ、管理、監視する方法をご紹介します。
今回は、Llama-3-8b-instructを例に説明します。
このモデルをUbiOpsでクラウドにデプロイし、モデルが使われるたびに、プロンプトとレスポンスのエンベッディングをメタデータと共にArizeに記録します。
こうすることで、Kubernetesや仮想マシンに煩わされることなく、スケーラブルな方法でllama-3-8b-instructをデプロイして提供できるだけでなく、LLMのパフォーマンスを注意深く見守ることができるようになります。
UbiOpsとは?
UbiOpsは強力なAIサービングとオーケストレーションのプラットフォームで、クラウドの知識がなくても、チームがAIとMLのワークロードを、信頼性が高くセキュアなマイクロサービスとして迅速にデプロイできるように支援します。
UbiOpsを使えば、クラウド、ハイブリッド、オンプレムなど、どのような環境でもAIモデルを大規模にデプロイできます。
Arizeとは?
Arizeは、AIの可観測性とLLM評価プラットフォームです。
Arizeを使用すると、LLMアプリケーションを監視、トレース、評価、反復することができます。
Arizeを使うことで、あなたのAIシステムを自信を持って本番稼動させることができます。
なぜllama-3-8b-instructを使うのか?
Llama 3はMeta社が開発したLlamaシリーズの最新モデルです。
コンパクトな80億パラメータバージョンと、より大きな700億パラメータバージョンの2つのサイズがあります。
どちらのモデルにも、ベースバージョンとインストラクターバージョンがあります。
Llama3のインストラクターバージョンは何が特別なのか?
インストラクション・バージョンは、インストラクション・チューニングが施されていることを意味します。
インストラクション・チューニングとは、単にプロンプトをこなすだけのベースモデルとは対照的に、質問に対して会話形式で応答するようにベースモデルを訓練するプロセスです。したがって、Llama3を微調整するのでなければ、インストラクションバージョンを使用することをお勧めします。
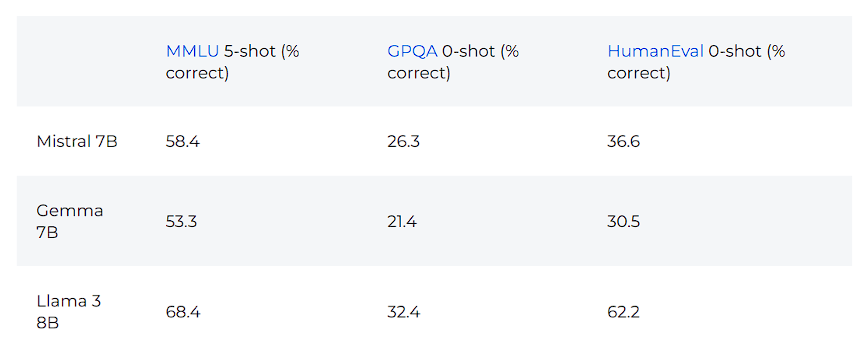
Meta社が発表した評価結果によると、Llama3 8Bは同サイズのMistral 7BやGemma 7Bを上回っています。
以下はその結果の表です。
オープンソースのLLMをインフラに導入する
まず、プレーン版のllama-3-8b-instructをUbiOpsにデプロイしましょう。
そのためには、UbiOpsにLLMを提供できるデプロイメントを作成する必要があります。
デプロイメントはUbiOps内のオブジェクトで、データを処理するPythonコードを提供します。
デプロイメントを作成するには、実行したいコードをUbiOpsに提供し、デプロイメントが必要とするハードウェアの種類などのデプロイメント設定を指定する必要があります。
作成後、UbiOpsはコードをコンテナ化し、自動スケーリングAPIエンドポイントを生成します。
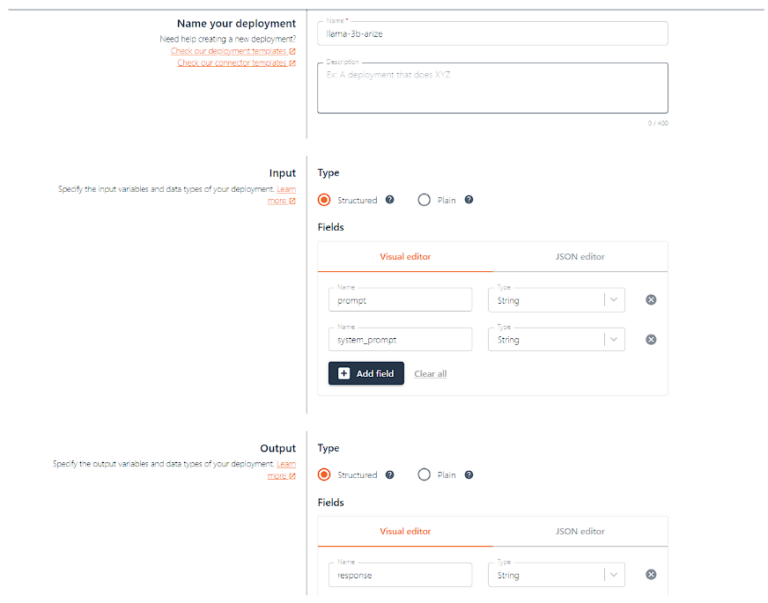
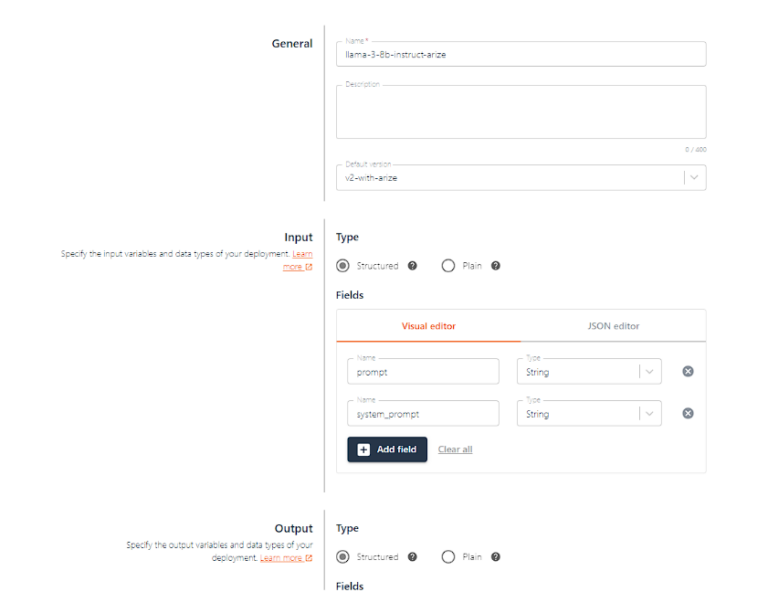
プロンプトとsystem_promptを入力として受け取り、レスポンスを返す新しいデプロイメントを作成してみましょう。
プロンプトはユーザーがLLMに送るプロンプトで、system_promptはモデルがどのように振る舞うべきかの指示です。
デプロイコードの作成
デプロイメントが作成されたので、私たちのコードでデプロイメント・バージョンを作成できます。
UbiOpsがいつ何を実行するかを理解するために、コードでは2つの関数を定義する必要があります。
Deploymentの初期化時に実行する必要があるものを指定する__init__関数、そして、新しいデータ(つまり新しいプロンプト)がモデルに送られたときに何が必要かを指定するrequest関数です。
以下に、Llama 3をUbiOpsにデプロイするためのデプロイメントコードを示します。
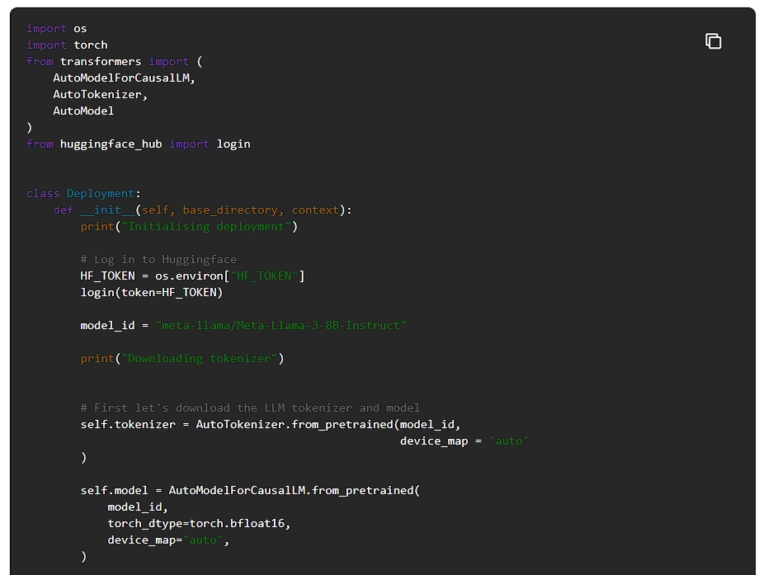
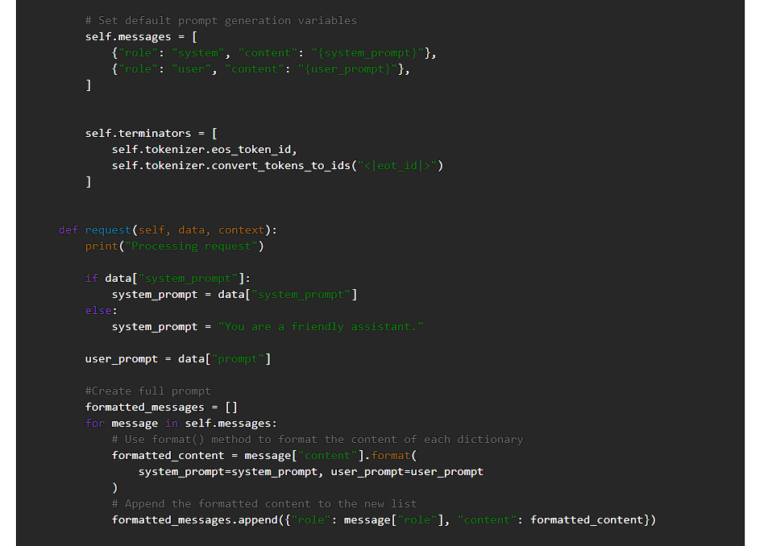
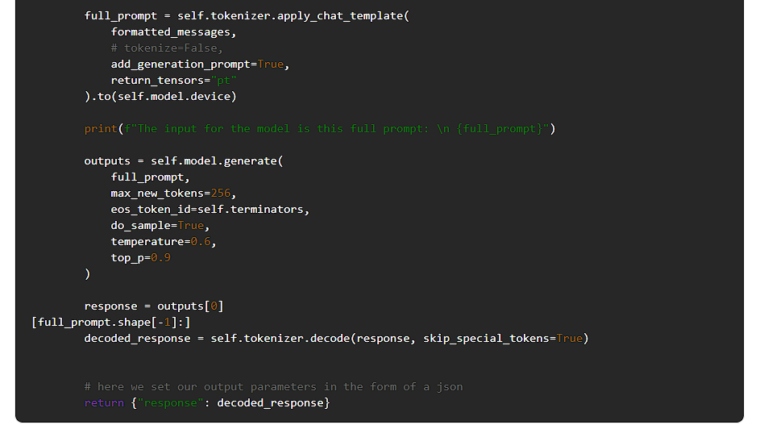
このコードを実行するには、requirements.txtで依存関係を指定する必要があります。
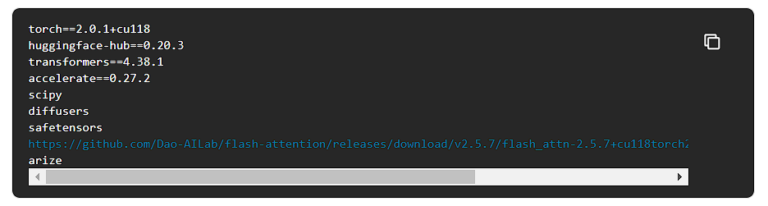
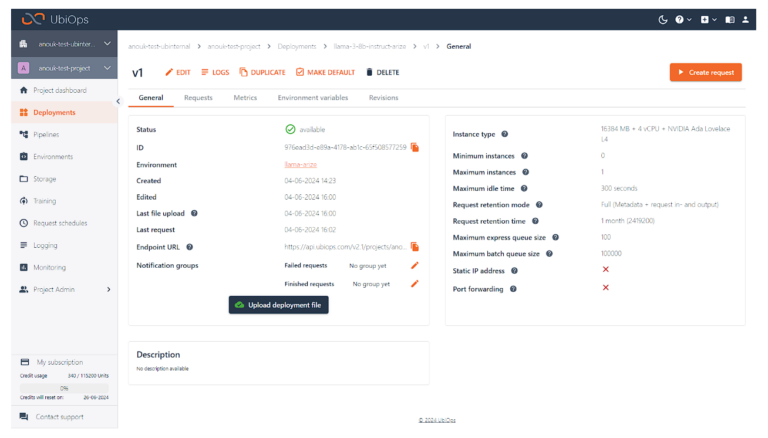
デプロイメント・バージョンを作成する
コードの準備ができたので、デプロイ・バージョンを作成していきます。
このバージョンは、十分に高速に実行するためにGPUが必要です。私たちはNVIDIA Ada Lovelace L4を使っています。Llama 3 8B-Instructデプロイメントパッケージをアップロードします。環境設定で、”Select code environment “ドロップダウンメニューからPython 3.11を選択します。
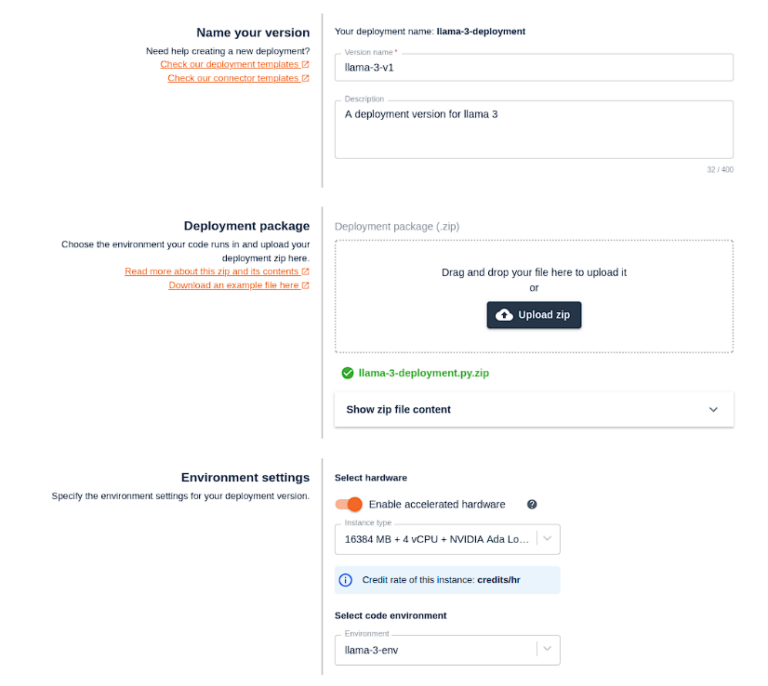
次に、モデルを実行するハードウェアを選択します。
このデプロイメントでは、アクセラレーションハードウェアを有効にし、16384MB + 4 vCPU + NVIDIA Ada Lovelace L4インスタンスを選択する必要があります。
HuggingFaceからLlama 3 8Bのインストラクションを引き出せるようにするには、Hugging Faceにサインインし、Meta-Llama-3-8B-InstructページでMetaのライセンス契約に同意し、HuggingFaceトークンをデプロイメントに提供する必要があります。
承諾後、Hugging Face内で、設定->アクセストークン->新しいトークンと進み、”read “権限を持つ新しいトークンを生成してください。
そしてトークンをクリップボードにコピーしてください。
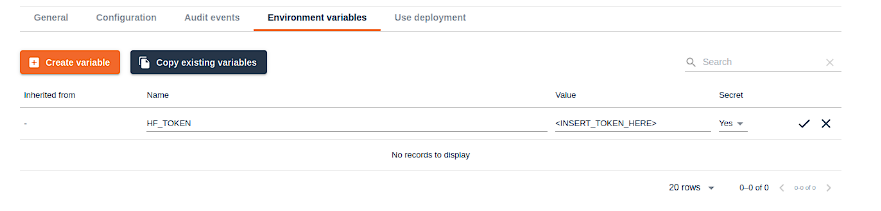
次に “deployment version create” フォームに戻り、Advanced/Optional settingsを展開します。環境変数セクションまでスクロールし、「変数を作成」をクリックします。
変数名を “HF_TOKEN “とし、値としてあなたのHugging Faceトークンを貼り付けます。トークンを安全に保つため、必ずシークレットとしてマークしてください。
createをクリックすると、UbiOpsがデプロイのビルドを開始します。ビルドが完了したら、Llama 3 8b Instructへの推論リクエストを行うことができます!
ArizeによるLLM観測可能性の追加
Arizeは、LLMシステムを監視するための多くの機能を提供しています。この例では、Arizeのエンベッディングモニタリング機能を使用します。
LLMのプロンプトとレスポンスのエンベッディングをモニターすることで、パフォーマンスを把握し、ドリフトを早期に発見することができます。
また、予期しないLLM応答などの問題を調査するのにも役立ちます。その前に、エンベッディングとは何かを簡単に説明しましょう。
embedding(埋め込み表現)とは何か?
埋め込みとは、データのベクトル(数学的)表現であり、線形距離が元のデータセットの構造を捉えることです。
このデータは単語で構成されることもあり、その場合は単語埋め込みと呼びます。しかし、埋め込みは画像や音声信号、さらには構造化されたデータの大きな塊を表現することもできます。
LLMのエンベッディングは、例えば入力プロンプトと生成された出力テキストの数学的表現です。
エンベッディングは、変換器、推薦エンジン、SVD行列分解、ディープ・ニューラル・ネットワークのレイヤー、エンコーダー、デコーダーなど、現代のディープラーニングのいたるところにあります。
エンベッディングの基礎となるのは以下の通りです。
- データを数学的に表現する
- データを圧縮する
- データ内の関係を保持する
深層学習レイヤーの出力であり、モデルによって学習された複雑な非線形の関係を、理解しやすい線形ビューで提供します。
エンベッディングを追跡することで、LLMアプリケーションの入出力データを監視することができます。これにより、データ・ドリフトのようなトピックを追跡・調査することができます。
詳しくはLLMOpsの学習モジュールをご覧ください。
Arizeで埋め込みを追跡する
Arizeはエンベッディングを記録し、時間経過とともにモニターすることができます。この例でこれを実現するには、プロンプト埋め込みとレスポンス埋め込みの両方を確実に追跡する必要があります。デプロイメントからArizeにエンベッディングをログできるようにするには、以下の手順が必要です。
- Arize APIクライアントとの接続設定
- エンベッディングの計算
- Arizeのクライアントでエンベッディングを記録する
ArizeAPIクライアントとの接続設定
接続を設定するには、ArizeスペースキーとAPIキーが必要です。
どちらもArize WebAppの “space settings “から取得できます。
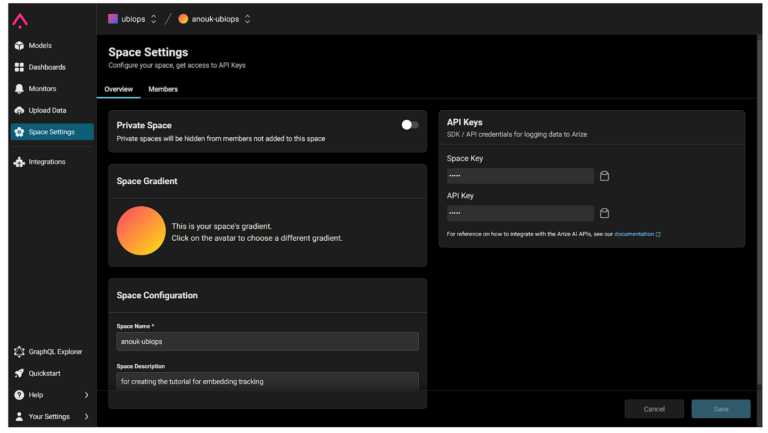
接続を確立するには、以下のコード・スニペットが必要となります。

埋め込みを計算する
埋め込みを計算するためには、埋め込みモデルが必要です。この例では、HuggingFaceのBAAI/bge-large-en-v1.5を使います。これは、非常に汎用的な英語の埋め込みモデルです。別の埋め込みモデルを使うこともできます。
HuggingFaceから埋め込みモデルを使用するには、次のように行います。

そして、このモデルを使って、プロンプトとレスポンスの埋め込みを次のように計算することができます。
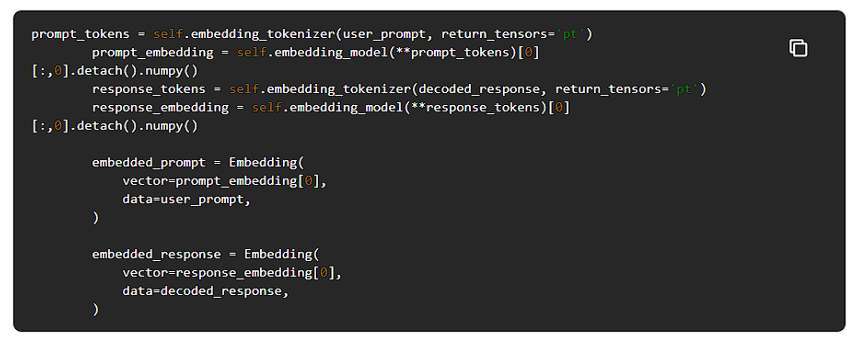
Arizeへの埋め込みログ
Arizeにエンベッディングを記録するには、モデル名、バージョン名、リクエストIDなどのメタデータと共にエンベッディングを記録する必要があります。
このメタデータは、UbiOpsがデプロイの__init__関数に送るコンテキストパラメータから取得できます。
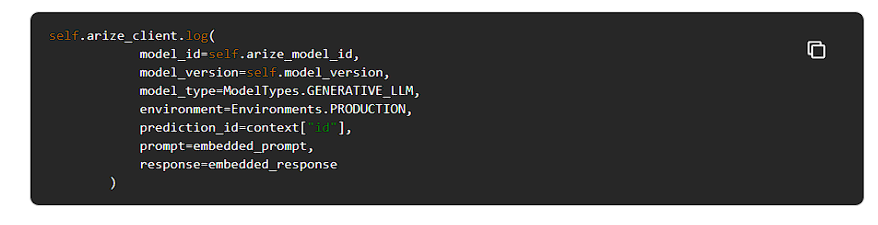
新しい配備コードにすべてをまとめる
これらのステップをすべて、先ほど作成したデプロイメントコードに統合すると、Llama 3を実行し、Arizeにプロンプトとレスポンスのエンベッディングを記録するdeployment.pyが完成します。
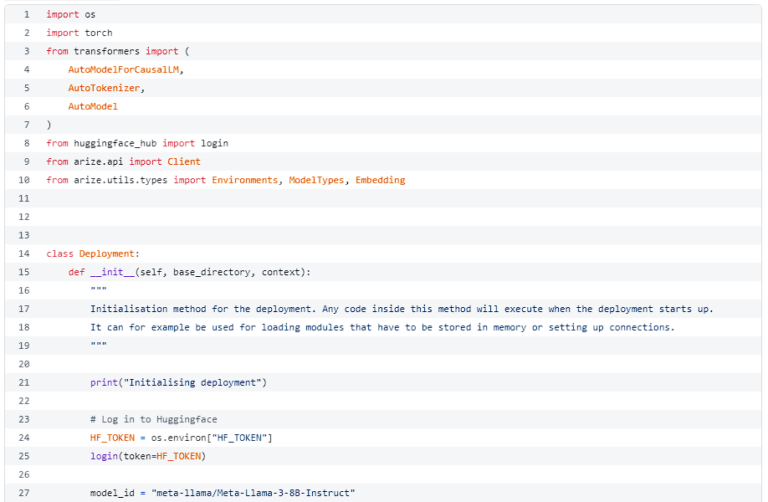



更新されたコードを入手したので、この追加機能を持つ新しいバージョンのデプロイメントを作成しましょう。
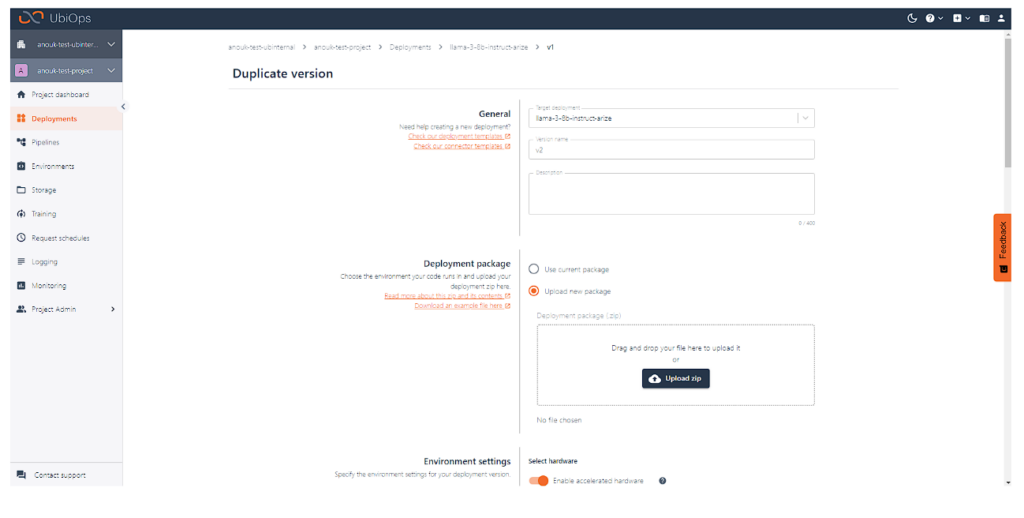
UbiOpsでデプロイメント バージョンを複製し、新しいデプロイメント パッケージをアップロードするオプションを選択します。
新しいパッケージには、Arizeにエンベッディングを記録するコードを含む更新バージョンを使用します。
作成をクリックすると、UbiOpsが新しいデプロイメント バージョンのビルドを開始します。
利用可能になったら、いくつかのリクエストを作成してテストすることができます。
結果の検査
UbiOps経由でデプロイメントにリクエストを送ると、Arizeにもリクエストが記録されるようになります。
LLMで様々な種類のプロンプトを使って試してみました。
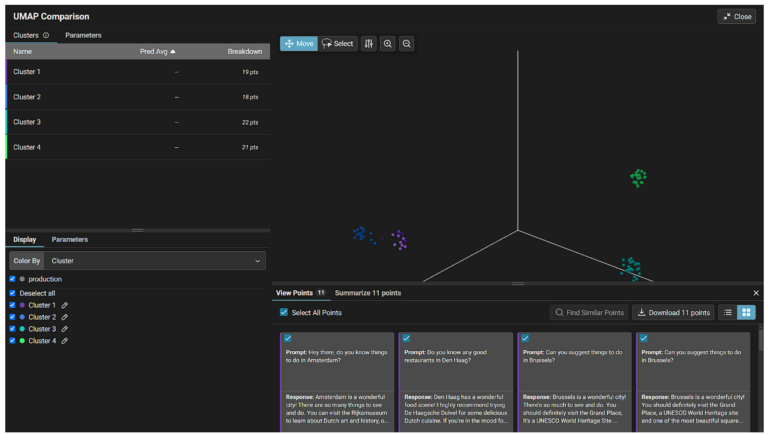
Arizeは生成されたembeddingsを自動的にクラスタリングしてくれるので、プロンプトやレスポンスの種類を判別したり、おかしな異常値を調査したりするのが簡単になりました。
ArizeプラットフォームでInferences > Embeddings projectorに移動すると、埋め込みデータを見ることができます。
個々のポイントにカーソルを合わせると、関連するモデルのプロンプト/レスポンスを見ることができます。
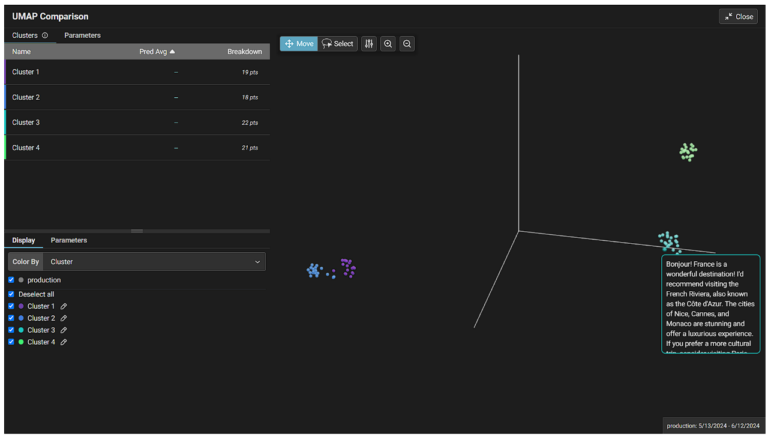
また、投げ縄ツールを使えば、特定のエリア内のすべてのポイントを素早く調査することも可能です。
結論
このガイドでは、UbiOpsを使ってLlama 3をクラウドにデプロイしただけでなく、Arizeを使ってLLMにモニタリング機能を組み込みました。
今回の例では、LLMのデプロイとモニタリングに関して氷山の一角に触れたに過ぎません。
これらのトピックをより深く掘り下げたい場合は、当社の他のブログ記事をご覧になるか、当社までご連絡ください!