検索とレスポンス・メトリクスによるLLMと検索補強世代のトラブルシューティング
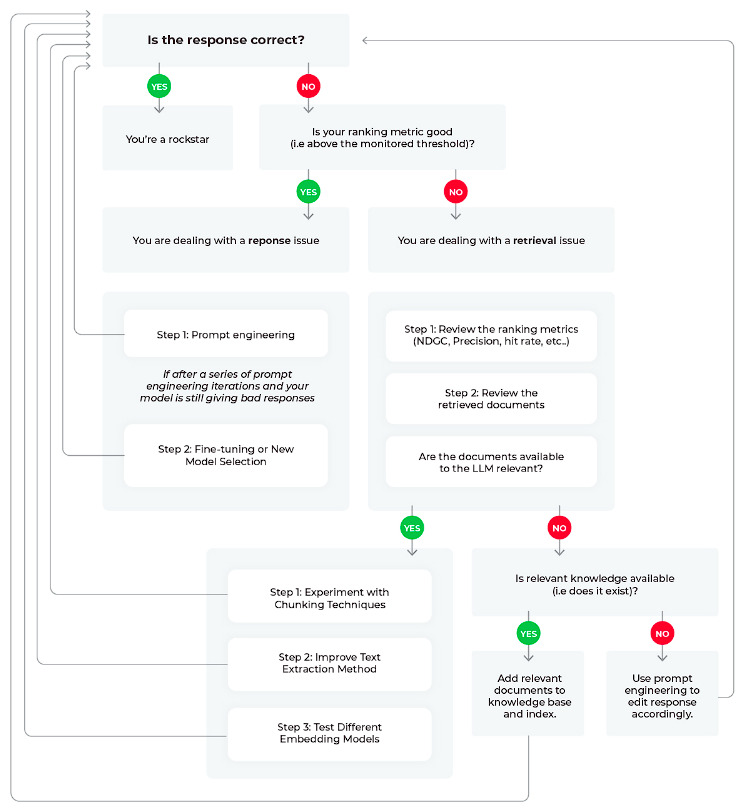
図1:LLM RAGアプリケーションの根本原因ワークフロー
検索タスクのために大規模言語モデル(LLM)を使って実験している場合、LLMが生成した応答に関連するコンテキスト情報を追加する技術として、検索拡張生成(RAG)に遭遇するでしょう。
LLMをプライベートデータに接続することで、RAGはコンテキストウィンドウに関連データを送り込み、より良い適切な回答を可能にします。
RAGは、複雑なクエリへの応答、知識集約的なタスク、AIモデルの応答の精度と関連性の強化に非常に有効であることが示されています。
しかしながら、RAGから得られるこれらの利点は、LLMシステムの一般的な障害ポイント、つまり応答と検索評価メトリクスを継続的にモニタリングしている場合にのみ享受することができます。
この記事では、不十分な検索とレスポンスのメトリクスを解消するための最適なワークフローについて説明します。
検索段階と回答のトラブルシューティング
RAGが最も機能するのは、必要な情報が容易に入手できる場合であることを忘れてはなりません。
関連文書が入手可能かどうかは、RAGシステムの評価を2つの重要な側面に集中させます。
- 検索評価: 検索された文書の正確さと関連性を評価する。
- 応答評価: コンテキストが提供されたとき、システムが生成したレスポンスの適切性を測定する。
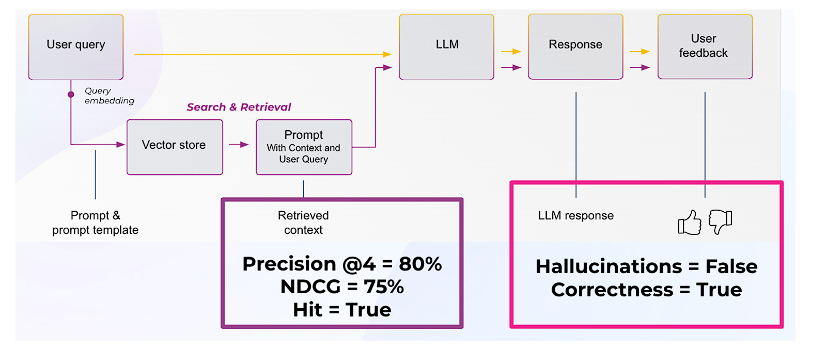
図2:LLMアプリケーションにおける検索評価と応答評価
レスポンス評価指標(表1)

検索評価指標(表2)

RAG評価: ワークフローのトラブルシューティング
フロー図に基づき、LLMのパフォーマンス低下をトラブルシューティングするために考えられる3つのシナリオを確認してみましょう。
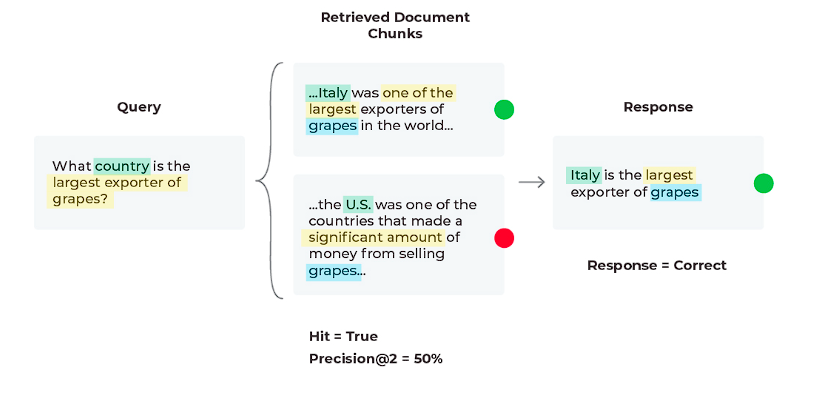
シナリオ1:良好なレスポンス、良好な検索
このシナリオでは、LLMアプリケーションのすべてが期待通りに動作しており、良好な検索結果とともに良好な応答が得られています。
レスポンスの評価は 「正しく」、「Hit = True 」であることがわかります。
「Hit」はバイナリ指標です。
「True 」は関連文書が検索されたことを意味し、「False 」は関連文書が検索されなかったことを意味しています。
Hitの集計統計はHit率(関連するコンテキストを持つクエリのパーセンテージ)であることにご注意ください。
私たちの応答評価では、「正しさ」は表1に見られるように、入力(クエリ)、出力(応答)、およびコンテキストの組み合わせで単純に行うことができる評価指標です。
LLMはOpenAIの関数呼び出しのようなツールでラベル、スコア、説明を生成するために使用することもできるので、これらの評価基準のいくつかは、ユーザがラベル付けした正解データ(教師データ)を必要としません。

これらの評価は、数値、カテゴリー(バイナリおよびマルチクラス)、マルチアウトプット(複数のスコアまたはラベル)のフォーマットで行うことができ、カテゴリーバイナリが最も一般的に使用されます。数値は一般的に使用されません。
シナリオ2:悪いレスポンス、悪い検索
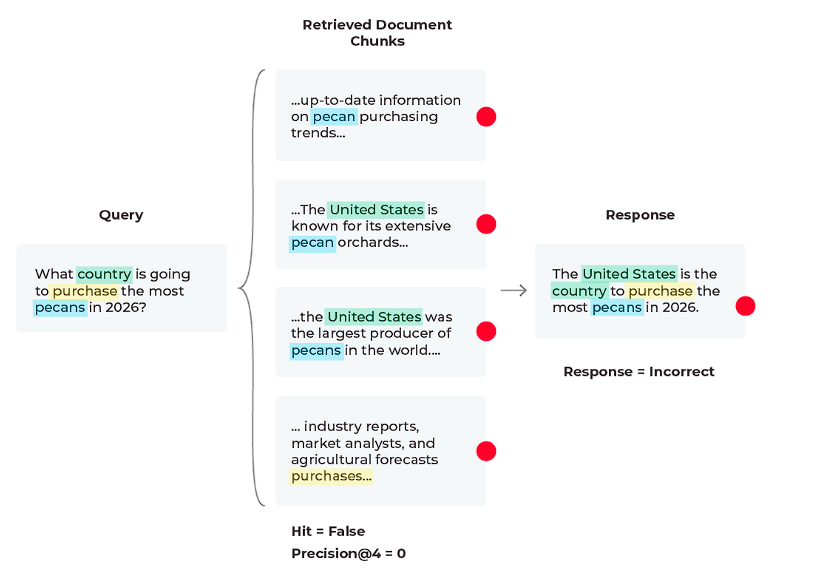
このシナリオでは、レスポンスが正しくなく、関連するコンテンツが取得できていないことがわかります。
クエリに基づくと、クエリに対する解決策がないため、コンテンツが受信されていないことがわかりますね。
LLMはどのような文書を供給されても、将来を予測することはできません。
しかし、LLMは答えを幻覚(ハルシネーション)で見るよりも良い回答を生成することができます。
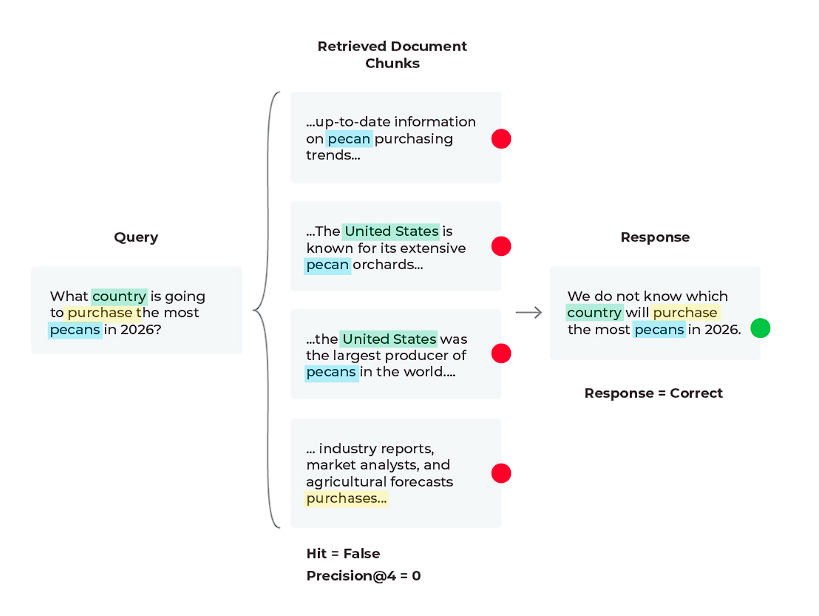
ここで、LLMのプロンプトテンプレートに「関連するコンテンツが提供されず、決定的な解決策が見つからない場合は、次のように回答してください」という行を追加するだけで、回答を生成しているプロンプトを実験することができるでしょう。
関連する内容が提供されず、決定的な解決策が見つからない場合は、答えは不明であると回答してください。
場合によっては、答えは存在しないというのが正しい答えとなることがあります。
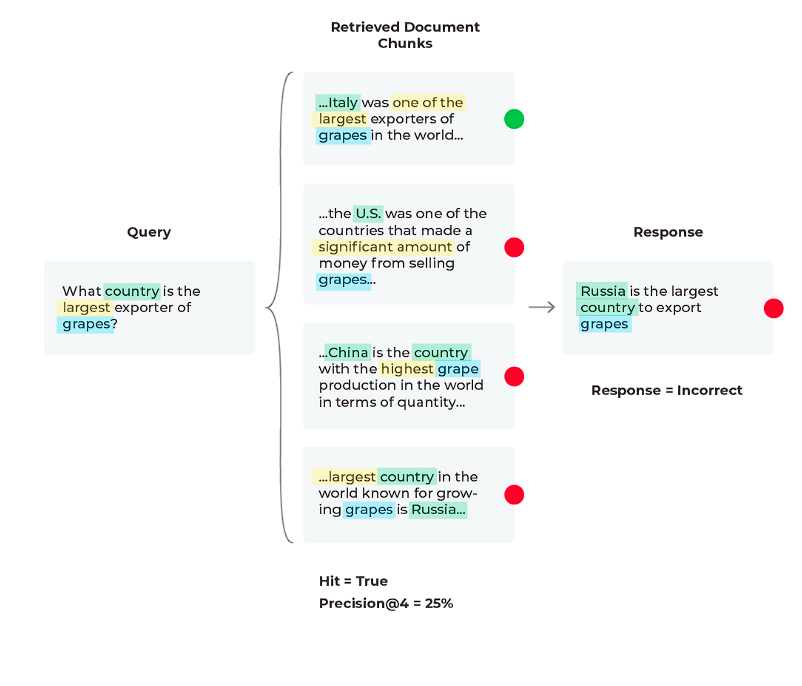
シナリオ3:悪いレスポンス、混合検索メトリクス
この3つ目のシナリオでは、検索メトリクスが混在した誤った回答が見られます(関連文書は検索されたが、LLMは情報が多すぎたために誤った回答を生成したというケースです)。
LLM RAGシステムを評価するには、適切なコンテキストを取得し、適切な答えを生成する必要があります。
通常、開発者はユーザークエリを埋め込み、それを使って関連するチャンクをベクターデータベースから検索します(図3参照)。
検索性能は、返されたチャンクがクエリと意味的に類似しているかどうかだけでなく、それらのチャンクがクエリに対する正しい応答を生成するのに十分な関連情報を提供しているかどうかにかかっています。

前回のシナリオと同様に、プロンプトテンプレートを編集するか、応答を生成するために使用するLLMを変更してみることができます。
関連するコンテンツはドキュメント検索プロセスで取得されますが、LLMでは表示されないため、これは迅速な解決策となります。
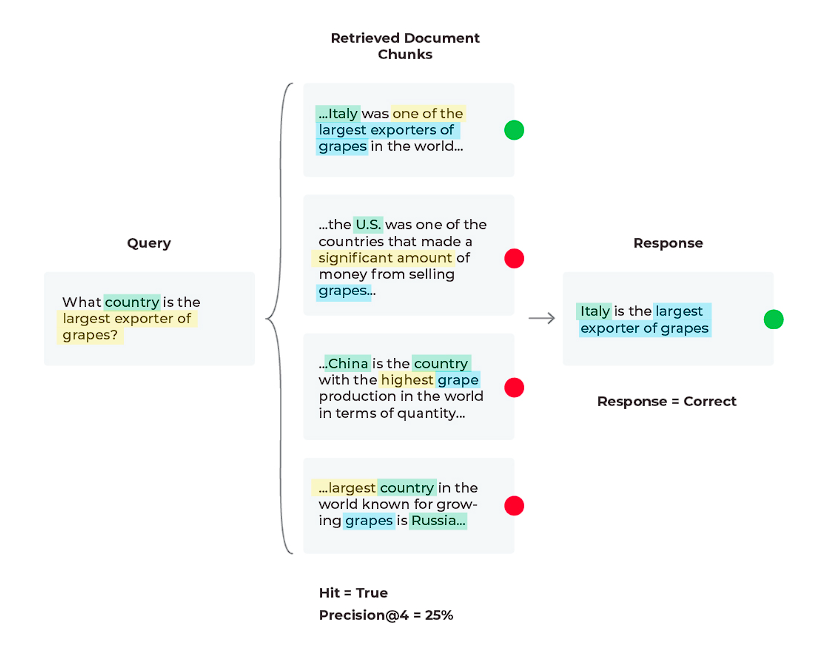
以下は、プロンプトの変数、LLMパラメータ、プロンプトテンプレートを繰り返し変更した後、プロンプトテンプレートを変更して正しい応答を生成した例です。
パフォーマンス・メトリクスが混在している悪い応答のトラブルシューティングを行う場合、どの検索メトリクスがパフォーマンス不足であるかを把握する必要があります。
これを行う最も簡単な方法は、しきい値とモニターを実装することです。特定のパフォーマンス不足のメトリクスがアラートされたら、特定のワークフローで解決できます。nDCGは上位にランクされたドキュメントの効果を測定するために使用され、関連するドキュメントの位置を考慮します。
この場合、関連ドキュメントを検索結果の上位に近づけるために、再ランク付けのテクニックを実装することを検討したくなると思います。
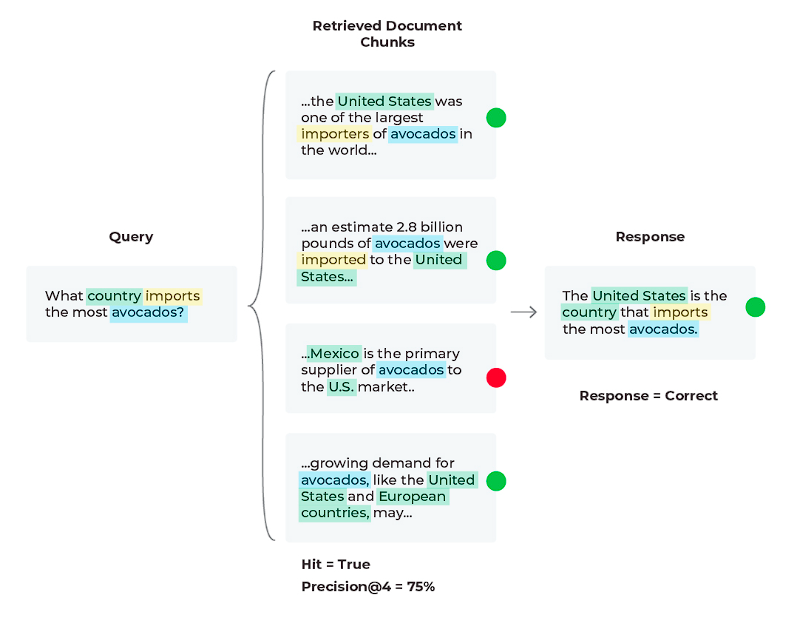
現在のシナリオでは、関連文書(Hit = ‘True’)を検索し、その文書が1位になっているので、検索された文書が’K’までの精度(関連文書の割合)を向上させてみましょう。
現在のPrecision@4は25%ですが、最初の2つの関連文書だけを使用すると、Precision@2 = 50%になります。
この変更により、LLMはより少ない情報しか与えられませんが、それに比例してより多くの関連情報を与えられるため、正しい応答が得られます。
本質的に私たちが見ていたのは、LLMが常に関連性のあるわけではない多くの情報に圧倒され、可能な限り最良の答えを出すことができなくなる「ロスト・イン・ザ・ミドル」と呼ばれるRAGの一般的な問題です。
この図から、チャンクサイズを調整することは、多くのチームがRAGアプリケーションを改善するために最初に行うことの1つであることがわかりますが、それは必ずしも直感的なものではありません。
コンテキストのオーバーフローや中途半端な問題では、ドキュメントが多ければ多いほど良いとは限らず、再ランク付けが必ずしもパフォーマンスを向上させるとは限りません。
どのチャンクサイズが最も効果的かを評価するには、evalベンチマークを定義し、チャンクサイズとtop-k値を掃引する必要があります。チャンキング戦略の実験に加え、様々なテキスト抽出技術や埋め込み方法を試すことも、RAG全体のパフォーマンスを向上させることにつながります。
全体のまとめ
今回試した応答と検索の評価指標へのアプローチは、LLM RAGシステムのパフォーマンスを包括的に見る方法を提供し、開発者と利用者がその長所と限界を理解するための指針となると思います。
これらの評価基準に対してこれらのシステムを継続的に評価することで、正確で関連性のあるタイムリーな情報を提供するRAGの能力を高めるための改善を行うことができます。
RAGを改善するための追加の高度な方法には、再ランキング、メタデータの添付、異なる埋め込みモデルのテスト、異なるインデックス作成方法のテスト、HyDeの実装、キーワード検索方法の実装、またはCohereドキュメントモード(Hydeに類似)の実装が含まれます。これらのより高度な方法(チャンキング、テキスト抽出、埋め込みモデルの実験)は、より文脈の一貫したチャンクを生成するかもしれませんが、これらの方法はより多くのリソースを必要とすることに注意しましょう。
RAGを高度な手法とともに使用することで、LLMシステムのパフォーマンスを向上させることができ、検索とレスポンスのメトリクスが適切にモニターされ、維持されている限り、その効果は継続するでしょう。